







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
风控中的一些数据分析思维(风控数据分析师是什么)
 2023-10-20
2023-10-20 浏览次数:次
浏览次数:次 返回列表
返回列表一、数据集背景
数据来源地址:https://pan.baidu.com/share/init?surl=ONrS1JbgL9ZrmMEvio49PA
数据源是2016Q2至2018Q2的数据,每个数据集都含有145个变量,我对数据集中的列进行了部分释义
数据集各个变量字段的业务含义(能力有限翻译出的32列变量含义,同时也是认为这些变量内容有可能会用于分析当中)

二、常用风控业务指标
1.逾期率指标:各家定义不一致,这里因数据集是以季度为单位的,所以定义一下为当季逾期贷款剩余本金/当季度放款总剩余本金,可以从横向比较一下坏账的波动
2.迁徙率指标:这里可以简单理解为贷款从某一状态进入到下一个状态的比例。如正常还款到M1期还款状态,M1变化成M2期还款状态,需要在通账龄下看
3.账龄分析Vintage图:不同放款时间在相同账龄下的表现。Vintage分析方法能很好地解决时滞性问题,其核心思想是对不同时期的放款的资产进行分别跟踪,按照账龄的长短进行同步对比,从而了解不同时期放款的资产质量情况,是一个所谓竖切的概念;而迁移率能很好的提示放款账户整个生命周期中的衍变情况,是一个所谓横切的概念。
4.不良率指标:各家定义不一致,通常是M3(60天以上)以后视为不良
5.净资产损失率:(成为坏账的金额-回收金额)/转坏账前应收
6.递延率指标:催收经常使用的绩效指标,指经催收后仍未缴款落入下一期的比例
7.首逾指数(疑似欺诈率):这里定义放款后第一期即未还款(通常二、三期仍不还款)的占到总放款件数的比例
8.进件相关指标:如进件数量,核准件数,黑名单命中率等
三、问题提出
对于本数据集提供的有关风控字段非常有限,基于此我在这里想了想可以分析的指标应是逾期率指标和首逾指标,那么我们就观察一下首期逾期的比例是怎么样变化的,同时关注一下环比是增加还是减少了,如果增加了是什么原因导致的。
四、数据清洗
1.选择子集并删除重复行
因为我们的数据集过大,会用到的字段有诸如贷款金额,贷款状态,迄今还款总额等等,为防止电脑在运行公式中卡顿,建议根据自己选择用到的变量进行腾挪,方法很简单,复制一份原始数据集到硬盘其他位置,之后把其他与本次分析无关的变量所在进行删除,保存重命名新的数据集“导出要分析的数据”。由于数据都是以客户的id作为唯一标识的,且数据方为了保护客户隐私故认为数据不存在重复。
2.对列明重新命名
接下来为了之后分析方便,对变量的名称进行翻译,同时如果英文阅读能力还可以的话,这里建议观测就不要翻译成中文了,数据字典中有详细解释(详细见数据集背景介绍)
3.缺失值的处理
要对观测为空值的数据进行检查,在检查各变量空值时,首先选择的是根据业务分析场景得到的没有空值一列的观测量,我的数据集中因为保护客户ID等隐私信息,故贷款状态一定是没有空值的变量,事实上也确实如此。记录该列观测数量并观察其他列,发现“每月债务收入比”与“信用额度占用比例”均有空值,因为我们的数据集观测数量很多,故在检查空值多少时发现信用额度占用百分比这列有83个空值,每月债务收入比这列有28个空值,选择了第二种方法(数据行为10^5级别,影响可以忽略不计)。那么这里还要介绍下如何快速筛选出这些空值的行。我选择的是全选该列,选择数据-升序或降序排列,同时在弹出的对话框里点选“扩展选定区域”,然后会发现所有为空值的都被甩在了队尾,故直接对这些数据行进行删除,重复此过程在另一列操作。
另外发现“工龄”这一列内容虽然无空值,但有无效值“n/a”,考虑到无法推断具体数字,故剔除掉这部分数据,方法同上。
4.数据的一致化处理
对于工龄这一列的处理方案是非数值型的数据,对其进行分列,分列的结果会发现工龄较大的一组人出现了“10+”,而“<1 year”工龄的人变成了“<”,这里需要对两类数据进行替换,用到“查找和选择”中的替换功能,把10+统一替换成10,把<1统一替换成1,方便后面的数据统计
当然为了后面在对工龄做分层时不要过于简单化的做一致化,保留其原始数据,因为如果把小于1年都看作是1年或把大于10年都看作是10年的话,会看不到结构的变化,所以至于要不要一致化要看后面要做什么。
至此数据清洗的工作就到此结束了
五、思路及分析
那么在构建思路和分析原因之前,首先看一下我对整体数据集首逾比例及环比情况的可视化结果吧【从后台分析数据中筛选出贷款状态非“Current”和非“Fully Paid”时迄今还款总额为0的即为首逾。那么用这个数据除以当季放款总件数即为比例。最终以季度为单位呈现环比状态】
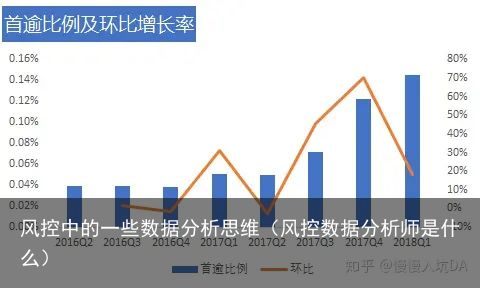
我们可以清楚的看出自2016年四季度往后首逾的比例再逐步升高,至2018年一季度数据已经达到0.14%,如果回溯至2016年二季度,数值呈现出了2.5倍的增长。环比增幅从17年的一季度开始就没有特别的漂亮过。
构思分析路径尽量通过数据抓手找到原因
先从外部原因开始
1.进件的客户自身结构是否发生变化:我的思路是整理出16Q4/17Q1/17Q4/18Q1四个季度进件客户的评级分布,处所分布,工龄分布,观察是否有变化,如何变化的
评级
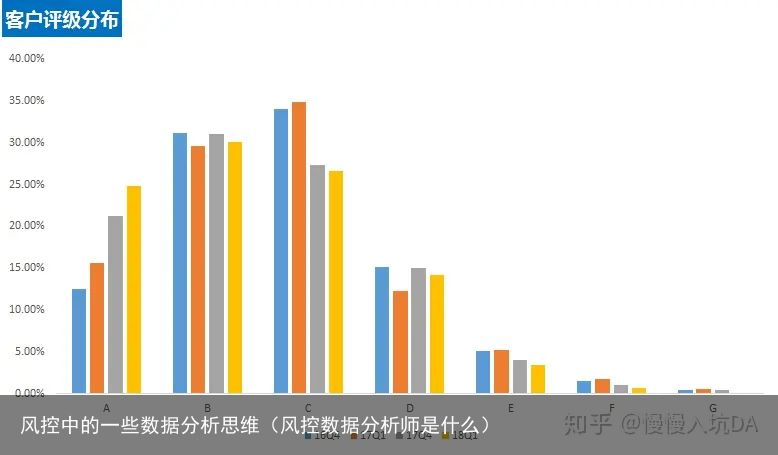 从信用评级来看评级优质的客户占比在增多
从信用评级来看评级优质的客户占比在增多处所分布
 由于州数较多,但经过数据观察发现各州在此四个季度的进件比例几乎未发生改变
由于州数较多,但经过数据观察发现各州在此四个季度的进件比例几乎未发生改变工龄分布
 工龄的分布也几乎没有发生改变,即便把1-3年4-6年7-9年这样类似分组加和呈现出来的比例也是几乎没有变化的,但需要指出的是低于1年工龄的客户在17年1季度有大幅增长
工龄的分布也几乎没有发生改变,即便把1-3年4-6年7-9年这样类似分组加和呈现出来的比例也是几乎没有变化的,但需要指出的是低于1年工龄的客户在17年1季度有大幅增长2.作为反欺诈的重要一环,机构线上在对疑似欺诈客户做尽调时一般会让客户提供某种资质补充件作为核验,而LC的客户在收入核验上分不同类别的,观察一下16Q4/17Q1/17Q4/18Q1四个季度的收入核验分布是否有变化,虽然这一项跟真实客户最终还款与否无相关关系,但对于本身就抱着骗贷的客户来说,敢提供假的资料都不会还款的。
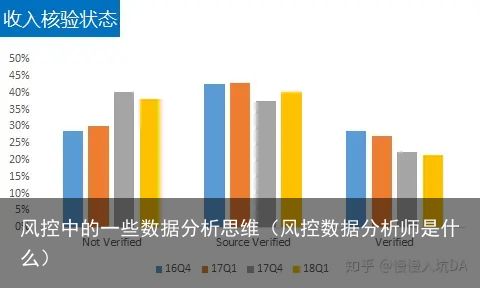 图中可以看到未进行核验的比例在走高,而靠三方机构核验和可验真的比例在下降
图中可以看到未进行核验的比例在走高,而靠三方机构核验和可验真的比例在下降3.这个是必须去横向比较的(LC自身数据集解决不了),需要去做同业公关调查。如果同业也发生了相同的趋向,那么可以说当前市场大环境导致欺诈客户增多,则需要调高反欺诈评分或调整规则。如果同业数据未发生大幅波动,则说明我们的反欺诈评分模型亟待调整,有可能某个权重项的规则被攻破,导致有很多欺诈客户通过了反欺诈这一关。【事后我查阅了一些相关资料,2017年度美国同业的坏账数据都在增加,且他们在意识到问题逐步恶化后均开始调整信用模型,尽管嘴上还在说自己的模型没有问题】
内部原因
1.核准通过是否有过放水,季度内是否有过重大政策调整
核准件数来看四个季度的数据分别为103546,96779,118648,107865,单从核准件数看波动不大,由于不清楚线上申请的总体数量,故暂时无法估计核准率上是否有大幅波动。至于季度内是否有重大政策调整需要进一步与政策部门确认。
2.自身反欺诈评分体系规则有无被攻破可能性,这一点其实在做横向比较时就可以的出来,如果只有己方首逾比例上升,那么显而易见的是当坏客户去别的地方申请不到贷款时,会选择来试一试己方的反欺诈规则,资料显示当时美国的整体坏账数据都在增加,所以重大规则别攻破的可能性很低很低,收紧反欺诈评分规则是当务之急
3.首逾客户特征是什么样的,与常规批核的客户有何不同
评级分布
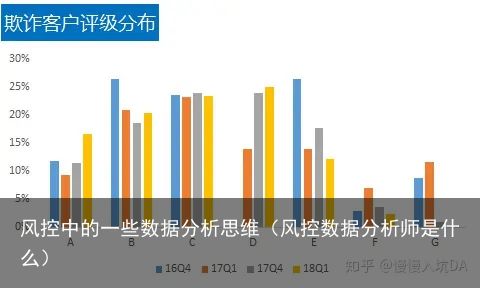 比较意外的是欺诈客户的信用评级分布多分布在B/C/D,而更差的F/G并没有占到主导地位,从另一方面说明了客户的欺诈行为和信用评级不成正相关
比较意外的是欺诈客户的信用评级分布多分布在B/C/D,而更差的F/G并没有占到主导地位,从另一方面说明了客户的欺诈行为和信用评级不成正相关处所分布
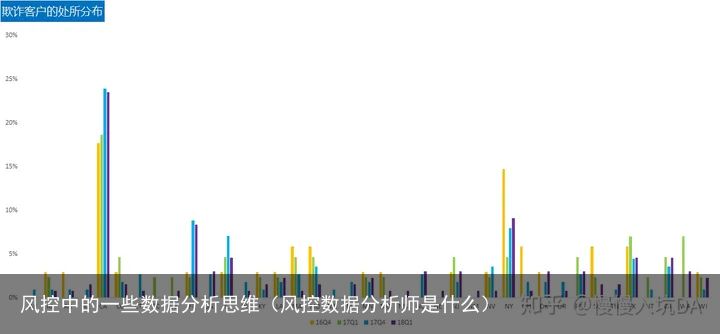
这里需要额外对比着核准客户处所的分布变化情况,由于之前分析过美国各州进件在这四个季度的变化几无差别,但这幅图中给我们呈现出来的是CA,FL,IL这三个州欺诈客户是在明显增多的,我们需要进一步去了解这些州是否发生了行业内部集体骗贷事件。
工龄分布
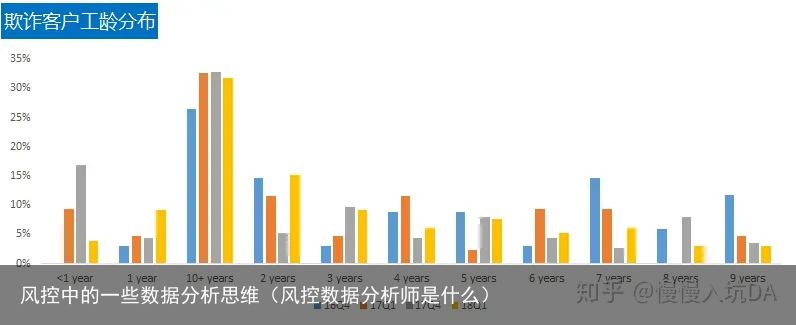 小于1年,1年工龄、3年工龄的人欺诈的比例在上升
小于1年,1年工龄、3年工龄的人欺诈的比例在上升六、结论建议
1.客户的信用评级没有影响着客户的欺诈行为,信用评级好的客户不代表不是欺诈客户,风控评级未失真。
2.新增欺诈客户的贡献多出自于美国的CA,FL,IL这三个州,需要深入调查行业内是否爆发集体关于此三州的恶性团体欺诈事件
3.LC客户的收入核验比例在下降有可能间接导致欺诈客户的流入,这一点需要寻找三方数据源把验真的比例提高起来
4.对于工龄小于3年的客户需重点防范欺诈风险
