







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据分析岗面试题【收集】(数据分析岗位面试题)
 2023-05-04
2023-05-04 浏览次数:次
浏览次数:次 返回列表
返回列表神奇的知识增加中>_<
爱数据-橙子:拼多多面经分享:24个「数据分析师」岗位面试题和答案解析495 赞同 · 28 评论文章一、统计知识
1.贝叶斯公式【补充】
条件概率: P(A|B)=P(AB)/P(B)P(A|B)=P(AB)/P(B)
引申: P(AB)=P(A|B)∗P(B)P(AB)=P(A|B)*P(B)
P(AB|C)=P(A|BC)∗P(B|C)P(AB|C)=P(A|BC)*P(B|C)
补充:
P(A|B)——在B条件下 A 的概率.即事件A 在另外一个事件B已经发生条件下的发生概率。
P(AB)——事件A、B同时发生的概率,即联合概率.联合概率表示百两个事件共同发生的概率.A 与 B 的联合概率表示为 P(AB) 或者 P(A,B)
由条件概率可得:
P(A,B)=P(A|B)⋅P(B)=P(B|A)⋅P(A)P(A,B)=P(A|B) \cdot P(B) = P(B|A) \cdot P(A)
由此得到贝叶斯公式的常规形式:
P(A|B)=P(B|A)P(A)P(B)P(A|B) = \frac{P(B|A)P(A)}{P(B)}
朴素贝叶斯的理解:在已知一些概率的情况下,由果索因
案例:一日某超市发生盗窃案,嫌疑人甲发生盗窃的可能性为10%,嫌疑人乙发生盗窃的可能性为90%,目击者称盗窃者是甲,目击者证言可信度为80%,那么现在请估算出目击者证言的准确度。
这里先假设:
嫌疑人甲发生盗窃的可能性为P(A)=10%,
嫌疑人乙发生盗窃的可能性为P(B)=90%,
目击者称盗窃者是甲可信度为P(C|A)=80%(解释:因为是建立在认为盗窃者就是甲的条件之上再判断目击者的话是否可信,所以P(C)指的是目击者证言可信度)
那么目击者指证乙的可信度为P(C|B)=20%,
那么目击者证词正确的概率为 :
P(A|C)=P(C|A)P(A)P(C)P(A|C)=\frac{P(C|A)P(A)}{P(C)}
P(C)=P(C|B)P(B)P(B|C)P(C)=\frac{P(C|B)P(B)}{P(B|C)}
P(B|C)=1−P(A|C)P(B|C)=1-P(A|C)
P(A|C)=P(C|A)P(A)(1−P(A|C))P(C|B)P(B)=0.8∗0.1∗(1−P(A|C))0.2∗0.9≈0.3076923076923077P(A|C)=\frac{P(C|A)P(A)(1-P(A|C))}{P(C|B)P(B)}=\frac{0.8*0.1*(1-P(A|C))}{0.2*0.9}\approx0.3076923076923077
四舍五入正确率30.77%
全概率公式
若事件B1,B2,...,BnB_1,B_2,...,B_n 是样本空间 Ω\Omega 的一个划分,则:
P(A)=∑i=1nP(A,Bi)P(A) = \sum_{i=1}^n P(A, B_i)
又因为条件概率公式,可进一步得:
P(A)=∑i=1nP(A|Bi)P(Bi)P(A) = \sum_{i=1}^n P(A|B_i)P(B_i)
全概率公式和贝叶斯公式的结合
P(A|B)=P(B|A)P(A)∑i=1nP(B|Ai)P(Ai)P(A|B) = \frac{P(B|A)P(A)}{\sum_{i=1}^n P(B|A_i)P(A_i)}
对数据分析感兴趣的小伙伴可以尝试下知乎推出的实战训练营,讲解该课程的是知名数据分析师猴子,课程适合零基础和想转行数据分析的新手小白,以及想在数据分析方面更进一步的从业者,3天课程实战训练营带你深入了解数据分析常用的相关性分析,帮助你提升数据分析思维,每天都有名师直播教授,无项目经验以及转行的小伙伴跟着课程完成项目实战作业,可以获得高质量项目的数据分析经验,解决无项目经验的求职难题,感兴趣的小伙伴点击下方链接,只需一毛钱即可体验高含金量的数据分析训练营,新的一年向着升职加薪前进!前 IBM 数据分析大咖 3 天实战训练营打工人升职加薪必备立即解锁二、SQL知识
如何写SQL求出中位数、平均数和众数(除了用count之外的方法)?我用的MYSQL,用上面链接里作者的代码行不通,所以修改了一下。
利用下面这个表:可以看到中位数用红框标记出了
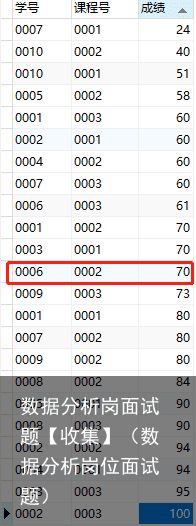
完整代码:
未考虑偶数:
SET @rownum=0; --设置序号列的标准代码 SELECT * FROM( SELECT @rownum:=@rownum+1 as rownum, `成绩表`.* FROM `成绩表` ORDER BY `成绩` )Y --将加入序号列的临时表命名为Y WHERE Y.rownum= (SELECT(count(*)+1) DIV 2 FROM `成绩表`)结果:

逐步分解:
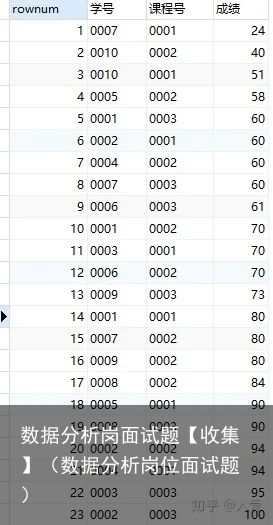
SELECT @rownum:=@rownum+1 as rownum , `成绩表`.* FROM `成绩表`
ORDER BY `成绩`
该段代码运行结果:
Y.rownum= (SELECT(count(*)+1) DIV 2 FROM `成绩表`)
count(*)计数行数,+1是解决奇数行的情况
通用代码:
考虑偶数情况:
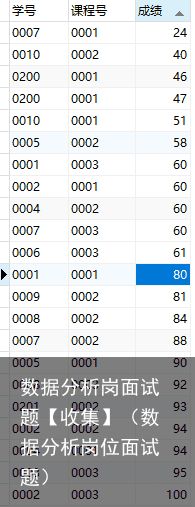 set @index = -1;
select avg(`成绩`) from
(select @index:=@index+1 as rownum, `成绩`
from `成绩表` order by `成绩`) as t
where t.rownum in (floor(@index/2),ceiling(@index/2));
set @index = -1;
select avg(`成绩`) from
(select @index:=@index+1 as rownum, `成绩`
from `成绩表` order by `成绩`) as t
where t.rownum in (floor(@index/2),ceiling(@index/2));
结果:
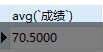
注解:
floor(@index/2):举例:floor(12.4)=12 floor(12.6)=12
ceiling(@index/2):举例:ceiling(12.4)=13 ceiling(12.6)=13
三、模型知识
1.如何避免决策树过拟合
限制树深剪枝限制叶节点数量正则化项增加数据bagging(subsample、subfeature、低维空间投影)数据增强(加入有杂质的数据)早停2.SVM的优点
优点:
能应用于非线性可分的情况最后分类时由支持向量决定,复杂度取决于支持向量的数目而不是样本空间的维度,避免了维度灾难具有鲁棒性:因为只使用少量支持向量,抓住关键样本,剔除冗余样本高维低样本下性能好,如文本分类缺点:
模型训练复杂度高难以适应多分类问题核函数选择没有较好的方法论3.Kmeans的原理
初始化k个点根据距离点归入k个类中更新k个类的类中心重复②③,直到收敛或达到迭代次数对数据分析感兴趣的小伙伴可以尝试下知乎推出的实战训练营,讲解该课程的是知名数据分析师猴子,课程适合零基础和想转行数据分析的新手小白,以及想在数据分析方面更进一步的从业者,3天课程实战训练营带你深入了解数据分析常用的相关性分析,帮助你提升数据分析思维,每天都有名师直播教授,无项目经验以及转行的小伙伴跟着课程完成项目实战作业,可以获得高质量项目的数据分析经验,解决无项目经验的求职难题,感兴趣的小伙伴点击下方链接,只需一毛钱即可体验高含金量的数据分析训练营,新的一年向着升职加薪前进!前 IBM 数据分析大咖 3 天实战训练营打工人升职加薪必备立即解锁四、业务知识
1.如何分析次日留存率下降的问题
业务问题关键是问对问题,然后才是拆解问题去解决。
1. 两层模型
从用户画像、渠道、产品、行为环节等角度细分,明确到底是哪里的次日留存率下降了
2. 指标拆解
次日留存率 = Σ 次日留存数 / 今日获客人数
3. 原因分析
内部:
运营活动产品变动技术故障设计漏洞(如产生可以撸羊毛的设计)外部:
竞品用户偏好节假日社会事件(如产生舆论)2.处理需求时的一般思路是什么,并举例
明确需求,需求方的目的是什么拆解任务制定可执行方案推进验收3.Mysql用户消费行为分析+回购率复购率
company_sql.csv266.7K · 百度网盘order_info_utf.csv20.7M · 百度网盘dataAnalyst_sql.csv734.1K · 百度网盘user_info_utf.csv1.3M · 百度网盘1)统计不同月份的下单人数
SELECT month(paidTime),COUNT(DISTINCT userid) FROM order_info_utf
WHERE isPaid=已支付
GROUP BY MONTH(paidTime);

2)统计用户三月份的回购率和复购率
复购率:一段时间内购买次数超过一次的占比
回购率:下一时间周期再次购买的人数占比
复购率:
SELECT COUNT(ct) ,COUNT(IF(ct>1,1,null)) , COUNT(IF(ct>1,1,null))/COUNT(ct) 复购率
FROM(
SELECT userid ,COUNT(userid) as ct
FROM order_info_utf
WHERE isPaid=已支付 AND month(paidTime)=3
GROUP BY userid) t;
注意:这里一定要给临时表创建一个名字(如这里的t),否则会报错。

回购率:这串代码效率极低,我的已经卡死了
SELECT t1.m,COUNT(t1.m),COUNT(t2.m) FROM
(SELECT userid ,DATE_FORMAT(paidTime,%Y-%m) AS m from order_info_utf
WHERE isPaid=已支付
GROUP BY userid,DATE_FORMAT(paidTime,%Y-%m)) t1
LEFT JOIN
(SELECT userid ,DATE_FORMAT(paidTime,%Y-%m) AS m from order_info_utf
WHERE isPaid=已支付
GROUP BY userid,DATE_FORMAT(paidTime,%Y-%m)) t2
on t1.userid=t2.userid AND t1.m=DATE_SUB(t2.m,INTERVAL 1 MONTH)
GROUP BY t1.m;
3)统计男女用户的消费频次是否有差异
SELECT sex, avg(ct) FROM(
SELECT o.userid, sex, COUNT(1) as ct
FROM order_info_utf o
INNER JOIN(
SELECT * FROM user_info_utf
WHERE sex<>)t
ON o.userid=t.userid
GROUP BY userid, sex) tt
GROUP BY sex;
*count小常识:
对于 count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
对于 count(1) 来说,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1) 执行得要比 count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据行,以及拷贝字段值的操作。
对于 count(字段) 来说:
如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。也就是前面的第一条原则,server 层要什么字段,InnoDB 就返回什么字段。但是 count(*) 是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定不是 null,按行累加。
4)统计多次消费的用户,第一次和最后一次消费间隔是多少
SELECT userid,
MAX(paidTime),
MIN(paidTime),
DATEDIFF(MAX(paidTime),MIN(paidTime)) 购买间隔天数
FROM order_info_utf
WHERE isPaid=已支付
GROUP BY userid
HAVING COUNT(1)>1;
5)统计不同年龄段,用户的消费金额是否有差异
SELECT age,avg(P) FROM( SELECT o.userid,age,sum(price) as P FROM order_info_utf o INNER JOIN (SELECT userid,CEIL((year(now())-year(birth))/10) age from user_info_utf WHERE birth>1901-00-00) t --年龄段分层 ON o.userid=t.userid GROUP BY o.userid,age) t2 --每个ID的年龄段及总消费金额 GROUP BY age ORDER BY age; --按年龄段分组,每个年龄段的平均消费金额6)统计消费的二八法则,消费的top20%用户,贡献了多少额度
SELECT COUNT(userid),SUM(total) FROM (
SELECT userid, SUM(price) as total FROM order_info_utf o
WHERE isPaid=已支付
GROUP BY userid
ORDER BY total DESC
LIMIT 17000)t;
