







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
如何进行探索性数据分析-数据挖掘01(以英雄联盟对局数据库为例)(探索性数据分析定义)
 2023-11-17
2023-11-17 浏览次数:次
浏览次数:次 返回列表
返回列表工作中经常会听到同时开玩笑般的戏称,小时候就梦想成为一个科学家,没想到长大后真的成为了数据科学家(Data scientist)。
既然叫做科学,那么一定会有一整套详细的数据分析框架。而探索性数据分析,无疑就是整个数据分析流程前期最为关键的一环。
回想起自己刚入行的时候,拿到数据就会迫不及待的套用各种模型——聚类、分类、回归。殊不知在探索性数据分析环节就可以用数据本身得到不少洞察,并决定下一步分析的走向。那么,在这一步骤主要需要进行一些什么工作呢?结合自己和同事的实践,一般至少会进行下面这三个步骤:
查看数据分布探究数据关联探索缺失值分布情况这里只是列出了我自己工作中的一些心得,段位越高的数据挖掘、数据分析师,自然会有更多的总结,也能从数据中获得更多的洞察。
以我手里的这份英雄联盟对局数据库为例,进行一些基础的说明~数据存储在Excel中,拿到数据集后,首先要做的是把数据集合读取到Python中。
import pandas as pd import numpy as np import warnings import dataprep.eda as eda pd.set_option(display.max_rows, 5) pd.set_option(display.max_columns, 500) pd.set_option(display.width, 1000) warnings.filterwarnings("ignore") lol = pd.read_excel(high_diamond_ranked_10min_missing.xlsx) lol_df = lol.iloc[:,:23]接下来我们可以看看这个数据集合到底包含多少条记录,有多少个指标
lol_df.shape
可以看到,该数据集合一共有9879条记录和23个指标。下一步则是从中挑选几列来理解一下指标的含义:
lol_df.head(3)
结合第一条数据来说明一下这些指标的含义到底为何,首先要介绍一下,这些记录是选取了钻石到王者段位的对局记录,数据选取时间为游戏进行的第10分钟。
以第一条记录为例,这是S8时期的一局比赛,平均段位为超凡大师,最终蓝色方输掉了比赛。游戏进行到10分钟的时候,蓝色方一共插了28个眼,排掉了2个眼位,蓝色方率先取得了一血。并且在10分钟的时候全队一共拿了9个人头。后面的字段应该都非常容易理解,在这里就不一一赘述了。
查看数据分布
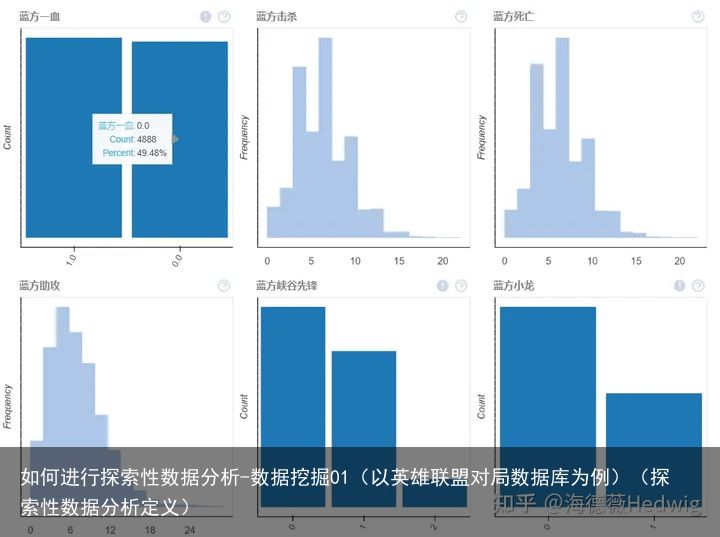
拿到这份数据之后,第一步一般会看一下数据的分布情况。借助dataprep包里面提供的函数,可以很轻松的实现这个目标。
eda.plot(lol_df)函数会为数据集中所有的分类型变量绘制条形图,而对于所有的数值型函数,则会绘制成直方图。
分类型变量以方一血为例,该数值取0的时候是红色方拿到一血的情况,可以看到大约49.48%的对局中,红色方拿到了一血。
数值型变量以蓝方击杀为例,可以看到大部分对局中,前10分钟蓝色方的击杀数集中在3-10之间。
如果对于蓝方击杀字段感兴趣,想要更加深入的探究蓝方击杀的细节,可以借助plot函数进行深入的探究
eda.plot(lol_df,"蓝方击杀")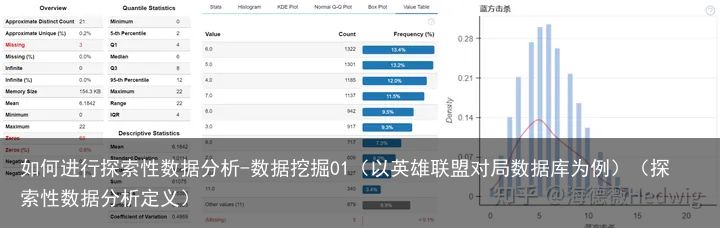
查看数据相关性
一般来说,数据分析的目的之一就是去寻找数据之间的关联,使用数据分析函数,同样可以很轻松的一键得到数值型变量的相关系数分布图。
但需要注意的是,相关系数仅仅能揭示数据之间的相关关系,而不能揭示因果关系。
比如从下图中我们可以看出,蓝方经济与蓝方补刀确实有很强的相关关系,但我们不能说因为蓝方的经济多,造成了蓝方的补刀也较多,这样的分析就是因果错乱的。
想要真正的了解每个数据之间的因果关系,需要我们对于数据本身的含义,有更深层次的理解。
eda.plot_correlation(lol_df)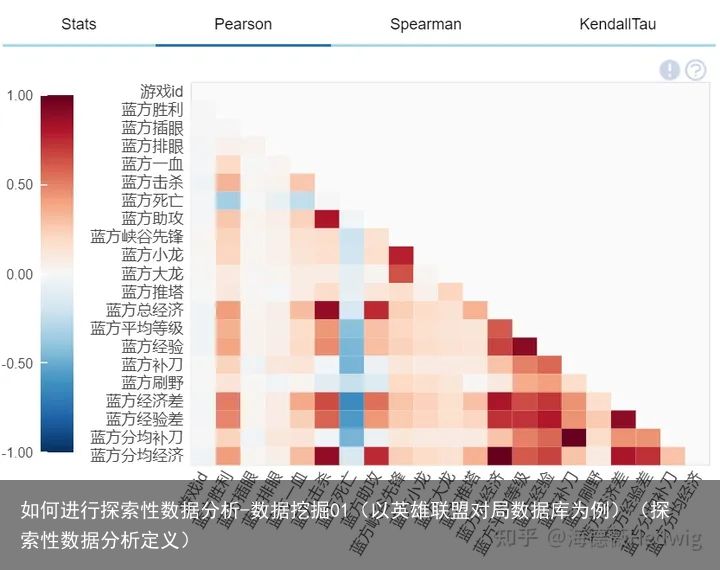
如果我们对于蓝方总经济格外关心,想要聚焦于蓝方总经济去探究哪些因素与其相关系数最大,那么也可以用下面的函数轻松做到。
从途中可以看出,与蓝方总计经济相关系数最大的是,蓝方分均经济、蓝方击杀和蓝方助攻。结合游戏内容来看,这些都不难理解。
eda.plot_correlation(lol_df,蓝方总经济)
这个数据分析函数的便捷之处就在于,几乎不需要任何的学习成本,直接调用函数就可以生成漂亮的数据分析报告,这将运用到最为关键的create_report()函数。
今天先更到这里,剩下的内容有空了再来更新。
