







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
这个“神器”帮助化工企业实现应用数据实时分析(化工产业数据)
 2023-10-09
2023-10-09 浏览次数:次
浏览次数:次 返回列表
返回列表某化工企业根据集团要求,需要获得业务系统的用户登录次数,查询报表名称和数量,查询时间等相关的内容,而他们使用的PowerBI系统将这部分内容都保存在日志文件中,需要实时获取日志文件,并进行解析,将解析的内容实时的保存到数据库中,并能够通过API接口的方式在界面上进行实时展现。
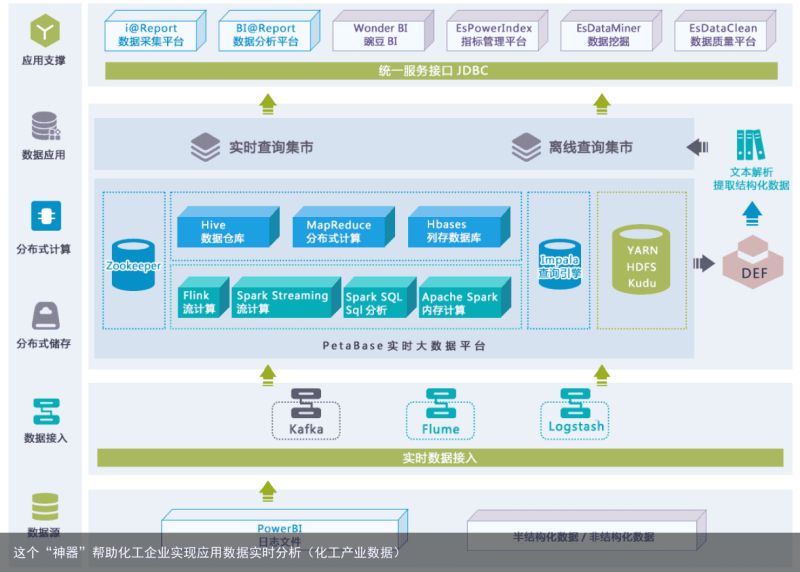
根据上述需求,亿信华辰数据专家组拟定了Petabase大数据平台+睿治数据治理平台的组合来实现,产品平台架构如下图:
 打开凤凰新闻,查看更多高清图片
打开凤凰新闻,查看更多高清图片方案分为六层:
第一层是数据源层,主要是指的源端数据,这里是powerBI的半结构化日志文件。
第二层是接入层,负责监听并实时采集pwerBI的增量日志内容,通过flume进行PowerBI日志文件的监听和实时摄取,摄取的文本消息下沉至Kafka消息队列中的topic。
第三层是数据存储层,负责整个平台的非结构化数据和结构化数据存储。其中,hdfs负责存储非结构化的日志文件,结构化的数据则使用kudu系统,以库表的形式进行存储。
第四层是计算层,负责对接入层的kafka消息流进行解析、汇总计算、入库和即席查询。 使用spark、impala分布式计算框架来支撑。
第五层是数据应用层,入库的结构化数据以关系表的形式,通过jdbc+sql的方式为应用层提供计算访问接口和服务。
第六层是应用支撑层,主要是华宇睿治产品,以友好的可视化方式向终端用户提供基于业务需求的数据访问和操作。除此之外,应用支撑层还能提供http、rest等主流的api接口为第三方应用提供数据访问服务。
使用睿治的资产数据接口对实时入库的数据进行界面展示,如下:
这样一来,不管多大数据量都可以实现实时分析,这其中提到了一个“神器”——PetaBase。
PetaBase是什么?
早期的PetaBase分布式数据库集成了Hdfs、MapReduce、Impala、Zookeeper、Hive共计5个主流组件,主要面向海量数据集的交互式联机分析场景。但是近年来,随着大数据的快速发展,对数据实时计算的要求越来越高,单一的分布式数据库已满足不了客户的需求,于是PetaBase-s实时大数据平台应运而生。
新版的PetaBase-s大数据平台采用了全新的企业级平台框架,集成了众多主流开源组件,不仅可以在海量的非结构化/半结构化/结构化数据集上同时进行离线计算和流式处理,还能满足高吞吐、大数据量和低时延实时处理等多方面的数据计算要求。
支持结构化数据的关联分析和OLAP应用,定位数据仓库和数据集市等分析型市场。
支持对高速数据流的接入与实时处理,实时探测关键事件,适合需要对变化数据进行连续计算并快速分析的场景。
基于开源Hadoop框架开发,融合MPP、SQL on Hadoop、流处理等大数据技术,支撑端到端的数据分析、数据洞察,快速构造从信息到智慧的大数据供应链。
PetaBase作为老牌商业智能厂商亿信华辰旗下的国产自主可控、可信、可靠的软件平台,可实现:源代码级的安全可控技术实现;国产操作系统的支持与持续更新;全组件HA并内置负载均衡功能;支持基于LDAP和Kerberos的认证及授权;与自研的 BI、数据治理产品相互支撑的优化保证真正意义上的一站式整体解决方案;工程化的开发与优化保证系统在生产环境的落地部署。
