







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
审计数据分析-数据获取专题经验分享(审计数据分析建模方法)
 2023-09-29
2023-09-29 浏览次数:次
浏览次数:次 返回列表
返回列表10月12日晚上8点30-9点30,Arbutus中国举办了一场针对审计数据获取的专题经验分享沙龙。沙龙深入浅出的讲解审计的数据环境、审计数据获取的目标、审计数据获取的困难、审计数据获取的标准化流程及审计数据获取的实际操作。并不是一场空洞乏味乱吹概念的沙龙分享会,而是实实在在,干货满满,看了能立马吸取到营养的经验分享会。
▼ Arbutus审计数据分享沙龙 ▼
数据获取专题分享-Arbutus审计数据分析沙龙第二期244 播放 · 0 赞同视频

- 审计数据分析 -
数据获取专题经验分享
▼
-01-
数据时代背景 | 数据获取目标
当前,企业的信息化系统建设日趋完善,企业的数据中心有很多个数据系统及数据库。但却没有专门为审计人打造的数据环境。专业数据库、各种格式的原始数据,是审计人目前面对的数据环境。
▼ 审计面对的数据环境 ▼
因此,有必要让审计人借助Arbutus可视化采集技术,自由又灵活地围绕着业务逻辑,从不同数据系统、数据库中采集数据,并将采集的数据统一为相同的数据格式,形成一个可供分析或结果汇报的“载体”。
▼ Arbutus可视化采集 ▼
- Part1总结 -
现实中,企业往往没有专门面向审计的数据环境。审计人在数据方面直接面对专业数据库及不同格式的数据文件。所以,有必要让审计人员借助Arbutus的可视化采集技术,自由而灵活的将满足业务逻辑的数据,从不同数据环境中整合到一个平台中。这是数据获取的一大核心目标。借助Arbutus可视化采集技术,能将数据获取的过程固化下来,确保取数过程是可重复、自动化的,同时能兼顾一次性取数及周期性取数,并自动完成数据校验及标准化。可部署,可自动运行,是数据获取的第二大核心目标。
-02-
数据获取的难点 | 及解决模式
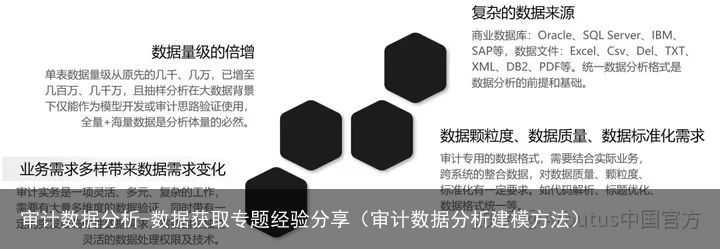
随着时代的发展及企业对数据建设的重视,业务数据的体量已从十几年前的几千、几万,提升到了几百万、几千万的量级。数据体量的倍增是数据获取的一大难点。不同业务产生的数据,往往存放于不同数据库或统一数据库的不同数据系统,这有利于数据管理,但也使数据需要从不同的数据源获取。复杂的数据来源是数据获取的第二大难点。这两大难点,是技术性的、客观的。
审计是一项灵活、多元、复杂的工作,不同业务的审计逻辑是不同的,业务需求的多样性直接促使审计数据需求的变化。数据需求多样性是审计数据获取的第三大难点。审计专用的数据格式,需要结合实际业务,跨系统的整合数据,对数据质量、颗粒度、标准化有一定要求。数据颗粒度、数据质量、数据标准化需求等细节处理,是数据获取的第四大难点。
▼ 数据获取的四大难点▼
困难是客观存在的,但明白了难点,针对性的解决它们就不是一件困难的事。在互联网领域,每一个困难,都可以通过“合适的工具+合适的应用模式”得到一个合适的解决方案。在审计数据获取方面,亦是如此。用Arbutus作为合适的工具+Arbutus提出的应用模式,即是审计数据分析合适的解决方案。
▼ 合适的解决方案 ▼

- Part2 总结 -
数据获取的四大难点是:
数据体量倍增数据需求多样数据来源复杂数据质量不尽相同解决问题的办法是:
合适的工具+合适的模式=合适的解决方案
Arbutus+数据获取流程=合适的审计数据分析解决方案
-03-
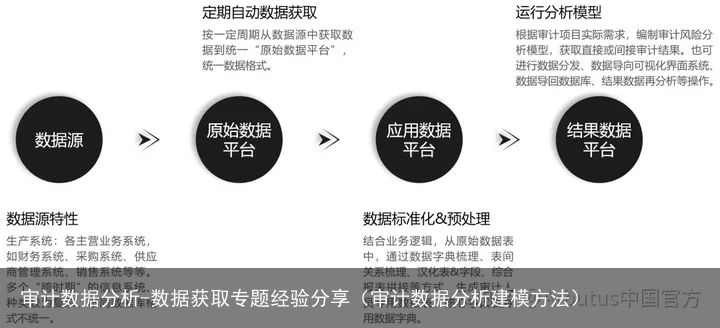
数据获取的标准流程 | 及对应结果
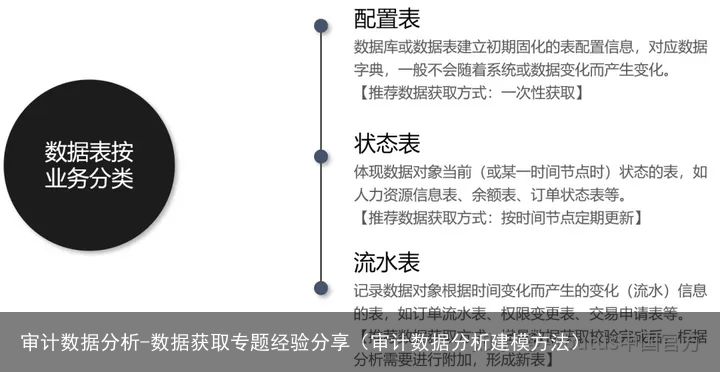
这一章节,分享的是千锤百炼的实践中,总结出来的一套真实的、可复用的数据获取标准流程。该流程将需要获取的数据表分为三类:状态表、流水表及配置表。
配置表—单次获取即可
数据库或数据表建立初期固化的表配置信息,对应数据字典,一般不会随着系统或数据变化而产生变化。
状态表—每次覆盖更新
体现数据对象当前(或某一时间节点时)状态的表,如人力资源信息表、余额表、订单状态表等。
流水表—不断增量附加
记录数据对象根据时间变化而产生的变化(流水)信息的表,如订单流水表、权限变更表、交易申请表等。
一个形象的例子是:每天查看支付宝的资产,余额、理财、余额宝就是一条条状态记录,形成的一张表就是状态表。支付宝账单,表示余额的变化,就是一条条流水,形成的一张表,就是流水表。点开帮助,帮助文档里对各个项目的解释,就可视为配置表。
▼ 状态表与流水表的图例 ▼

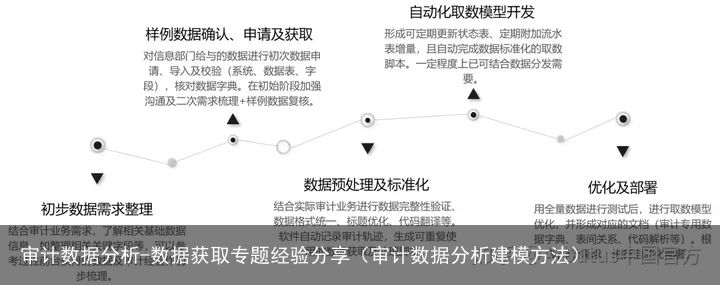
流程的前两步,是数据需求梳理与样例数据核对。这需要审计部与数据中心建立流畅的沟通体系,根据审计实践积累的经验、想到的数据线索,按照业务逻辑整理出一份数据需求文档,请数据中心提供数据,然后,结合业务逻辑核对数据。这是一件知易行难的事,关于此,可参考我们前一期的推文:《打破数据壁垒—清单管理法》,文中我们针对这两步,分享了一套“可行的”解决方法。
借助Arbutus可视化技术,确定目标数据表后,数据获取极为容易。通过鼠标点选即可完成数据获取,并将过程固化为可部署、可复用的取数脚本。
获取到的数据,需结合实际审计业务逻辑,进行数据完整性验证、数据格式统一、字段名称及类型优化等标准化及预处理操作,确保数据颗粒度、数据质量能切实满足分析需要。
最后,将Arbutus可视化操作得到的数据获取脚本、数据标准化脚本、数据预处理脚本整合在一起,即完成自动化取数模型开发。通过Arbutus的任务计划功能,完成数据获取任务的固定周期自动化运行部署。
(篇幅限制,此处不过于展开)
(意犹未尽可在官方号回看沙龙视频)
▼ 数据获取的标准流程 ▼
- Part3 总结 -
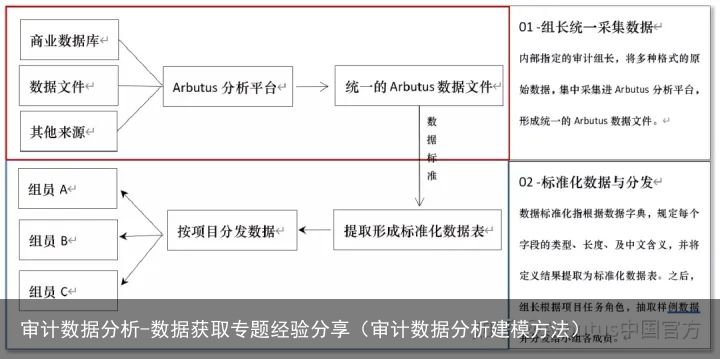
用通俗的语言说,数据获取的标准流程:
先想想自己要什么数据,然后找数据中心拿一点样例来验证一下,如此反复,直到确定本次审计项目需要的所有数据表。(第一步、第二步)
而后,借助Arbutus可视化采集工具,从数据中心指定的地方,将所有数据表采集进Arbutus。然后,验证数据完整性,并根据数据字典,优化字段名称、字段类型。而后,将数据表按照既定的状态表、流水表分类,确定不同的更新方法。是流水表的,以后的数据表追加在旧的下面,是状态表的,以后的数据表直接覆盖更新。(第二步、第三步)
第一步、第二步、第三步形成的脚本合在一起,就是自动化数据获取的脚本。(第四步)
使用Arbutus任务计划功能,指定频率、周期,实现定时定点的数据获取(第五步)
