







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
企业搭建大数据分析平台整体方案思路(企业实施大数据营销应具备的条件)
 2023-04-25
2023-04-25 浏览次数:次
浏览次数:次 返回列表
返回列表一般的大数据平台从平台搭建到数据分析大概包括以下几个步骤:
 打开凤凰新闻,查看更多高清图片
打开凤凰新闻,查看更多高清图片1、Linux系统安装
一般使用开源版的Redhat系统--CentOS作为底层平台。为了提供稳定的硬件基础,在给硬盘做RAID和挂载数据存储节点的时,需要按情况配置。比如,可以选择给HDFS的namenode做RAID2以提高其稳定性,将数据存储与操作系统分别放置在不同硬盘上,以确保操作系统的正常运行。
2、分布式计算平台/组件安装
当前分布式系统的大多使用的是Hadoop系列开源系统。Hadoop的核心是HDFS,一个分布式的文件系统。在其基础上常用的组件有Yarn、Zookeeper、Hive、Hbase、Sqoop、Impala、ElasticSearch、Spark等。
使用开源组件的优点:1)使用者众多,很多bug可以在网上找的答案(这往往是开发中最耗时的地方);2)开源组件一般免费,学习和维护相对方便;3)开源组件一般会持续更新;4)因为代码开源,如果出现bug可自由对源码作修改维护。
常用的分布式数据数据仓库有Hive、Hbase。Hive可以用SQL查询,Hbase可以快速读取行。外部数据库导入导出需要用到Sqoop。Sqoop将数据从Oracle、MySQL等传统数据库导入Hive或Hbase。Zookeeper是提供数据同步服务, Impala是对hive的一个补充,可以实现高效的SQL查询
3、数据导入
前面提到,数据导入的工具是Sqoop。它可以将数据从文件或者传统数据库导入到分布式平台。
4、数据分析
数据分析一般包括两个阶段:数据预处理和数据建模分析。
数据预处理是为后面的建模分析做准备,主要工作时从海量数据中提取可用特征,建立大宽表。这个过程可能会用到Hive SQL,Spark QL和Impala。
数据建模分析是针对预处理提取的特征/数据建模,得到想要的结果。如前面所提到的,这一块最好用的是Spark。常用的机器学习算法,如朴素贝叶斯、逻辑回归、决策树、神经网络、TFIDF、协同过滤等,都已经在ML lib里面,调用比较方便。
5、结果可视化及输出API
可视化一般式对结果或部分原始数据做展示。一般有两种情况,行数据展示,和列查找展示。
企业搭建大数据分析平台的背景
1、搭建大数据平台离不开BI。在大数据之前,BI就已经存在很久了,简单把大数据等同于BI,明显是不恰当的。但两者又是紧密关联的,相辅相成的。BI是达成业务管理的应用工具,没有BI,大数据就没有了价值转化的工具,就无法把数据的价值呈现给用户,也就无法有效地支撑企业经营管理决策;大数据则是基础,没有大数据,BI就失去了存在的基础,没有办法快速、实时、高效地处理数据,支撑应用。 所以,数据的价值发挥,大数据平台的建设,必然是囊括了大数据处理与BI应用分析建设的。
2、大数据拥有价值。来看看数据使用金字塔模型,从数据的使用角度来看,数据基本有以下使用方式:
自上而下,可以看到,对数据的要求是不一样的:
数据量越来越大,维度越来越多。
交互难度越来越大。
技术难度越来越大。
以人为主,逐步向机器为主。
用户专业程度逐步提升,门槛越来越高。
企业对数据、效率要求的逐步提高,也给大数据提供了展现能力的平台。企业构建大数据平台,归根到底是构建企业的数据资产运营中心,发挥数据的价值,支撑企业的发展。
整体方案思路如下:
建设企业的基础数据中心,构建企业统一的数据存储体系,统一进行数据建模,为数据的价值呈现奠定基础。同时数据处理能力下沉,建设集中的数据处理中心,提供强大的数据处理能力;通过统一的数据管理监控体系,保障系统的稳定运行。有了数据基础,构建统一的BI应用中心,满足业务需求,体现数据价值。
通过数据平台和BI应用建设,他们可以搭建统一的大数据共享和分析平台,对各类业务进行前瞻性预测分析,并为集团各层次用户提供统一的决策分析支持,提升数据共享与流转能力。搭建一套成熟的大数据分析平台是一项复杂的工作,因此选择一个合适的BI工具显得尤为重要。
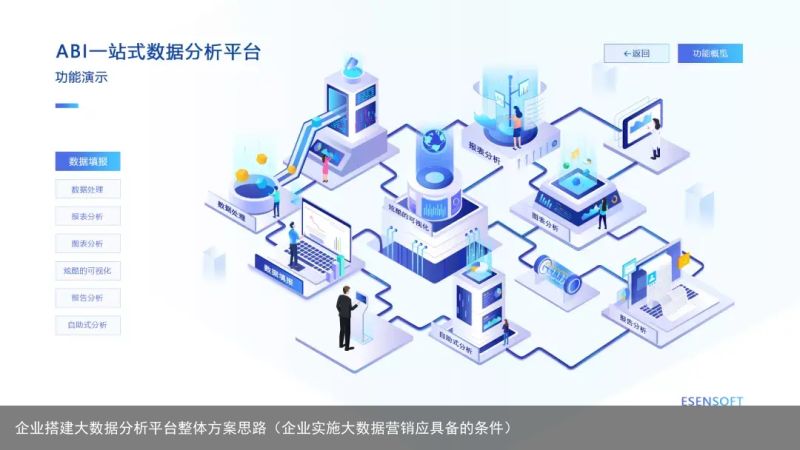
亿信ABI是一款融合了数据源适配、ETL数据处理、数据建模、数据分析、数据填报、工作流、门户、移动应用等核心功能而打造的全能型数据分析平台,提供了多种分析手段,在可视化分析方面支持复杂报表、Dashboard、3D可视化、大屏分析、GIS地图、预测挖掘等,在自助式分析方面支持敏捷看板、即席报告、幻灯片、移动分析等分析方式,以满足用户各种分析场景。希望对你有所帮助。
