![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
探索性数据分析|Exploratory Data Analysis|EDA 入门(基本概念、流程、工具及资源)
 2023-03-20
2023-03-20 浏览次数:次
浏览次数:次 返回列表
返回列表写在前面:
最近两个月一直在搞数据。。。。记录一下心酸过程的收获
本文受众包括有数据分析需要的科研小白、python初学者。需要读者具有基本的统计知识
一、概念
1. 什么是探索性数据分析?
探索性数据分析(EDA)[1]是由数据科学家用来分析和调查数据集,并总结其主要特征,通常采用数据可视化方法。它有助于确定如何最好地操作数据源以获得你所需要的答案,使数据科学家更容易发现模式,发现异常,测试一个假设,或检查假设。
EDA的主要目的是做出任何假设之前帮助观察数据。它可以帮助识别明显的错误,以及更好地理解数据中的模式,检测异常值或异常事件,找到变量间的有趣关系。
2. 为什么要做探索性数据分析?
对数据集更深的理解(分布、缺失等统计信息)获得高质量的数据集(异常值、缺失值的基本处理)机器学习模型、实证假设构建的思路(灵感)二、基本的流程与步骤
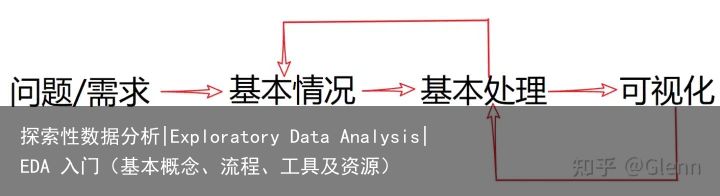
1. 问题/需求 导向
基本前提:数据+问题
具有一定数量的数据集:数据越多,所涵盖的信息量越大。如果数据过少(10条以下),那就没有做EDA的必要了,因为你完全可以一眼看出数据的基本特性(缺失、异常、分布等)
基于这个数据需要解决的问题:
需要明确你的问题,以及这个数据所提供的信息是否能解决你的问题。假如我想知道某小学的男孩子的年龄分布信息,而数据集是女孩子的,那很抱歉,这个数据不使用你的问题。
假如问题不明确,那你可能在EDA的过程中反复迭代,无法收敛,,,,
PS:当然了,如果你新入手了一个数据集,但是不明确你的问题,那也可以做一下EDA,说不定能发现一些有意思的结果,满足你小论文的需要
2. 数据的基本情况了解
包括但不限于:
数据量、特征数量、数据类型数据分布情况(标准差、分位数、最大最小值)3. 数据的基本处理
基于2的信息进行数据处理
Tips:对于数据的处理方式根据你的问题需要进行选择。如果数据的某一个特征值缺失了,但对于我的目标没有影响(我不会用这个特征进行模型的训练),同时数据量又比较少,那肯定选择保留这个数据;反之,如果我要用这个特征进行训练,但该值缺失了,那就选择删除该数据,或者你的数据量非常大,那你可以选择无脑删除
重复值处理(保留、删除):假如你想发现某个用户的行为模式,该用户在不同的时间点进行相同的操作,那这个重复值是不是能帮助你获取该用户的行为偏好(你的问题),那可以保留异常值处理(保留、删除):假如你正在做异常检测的任务,那这个信息能帮助你进行有效的数据标注(你的需要)缺失值处理(删除、填充)4. 数据的可视化
单变量可视化:查看数据分布-直方图、箱线图:
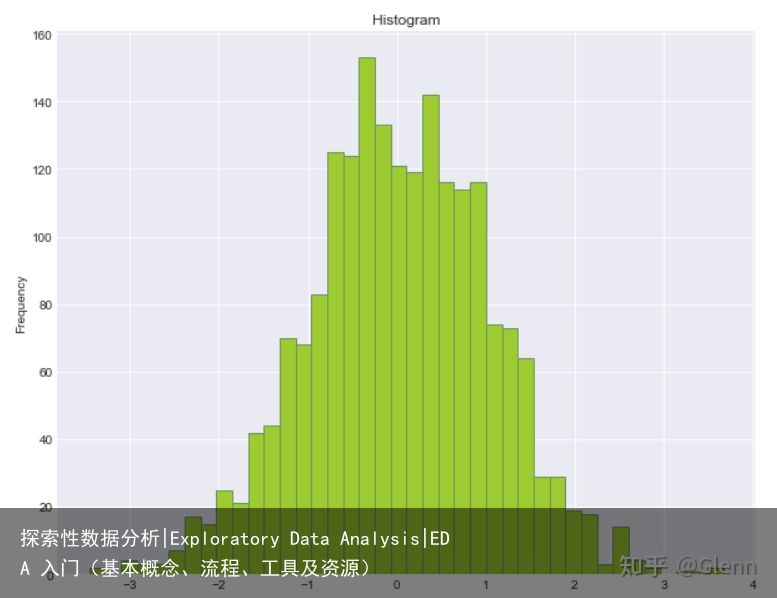 直方图
直方图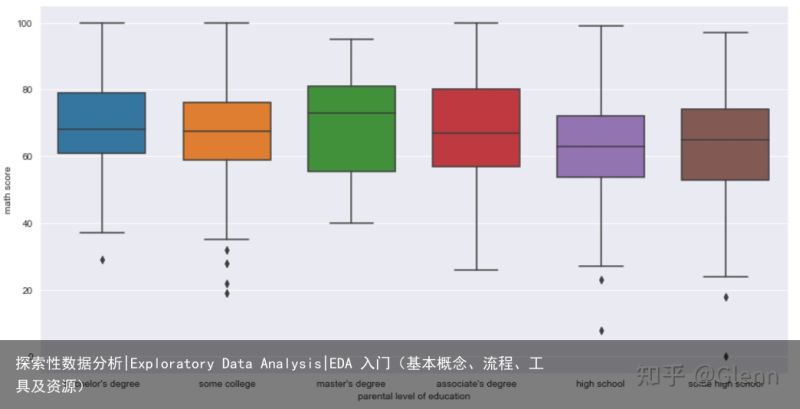
两个变量的可视化:相关性分析-线图、散点图、热力图
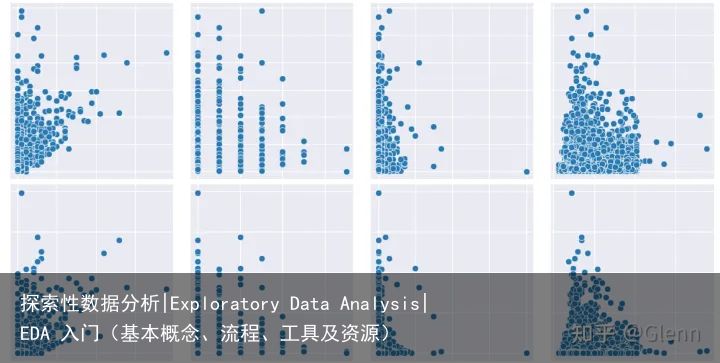 散点图
散点图 线图
线图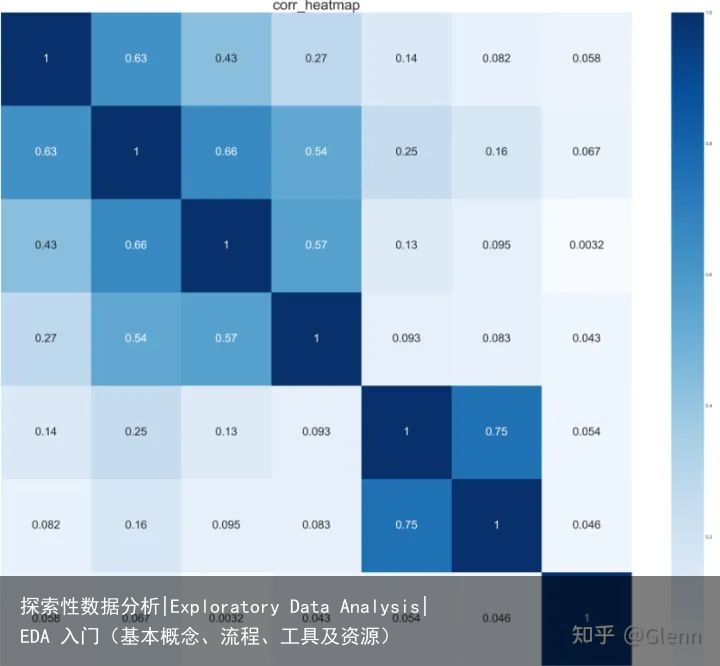 热力图
热力图时间维度的可视化:时间序列分析-线图
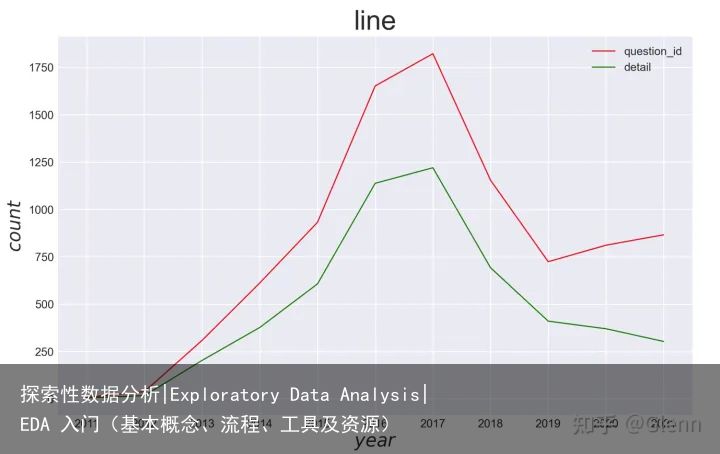 按年
按年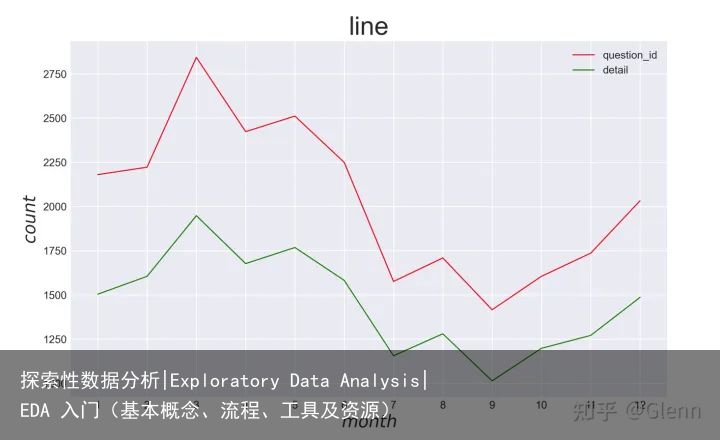 按月
按月三、选择的工具
1. 编译器选择
pycharm敲代码、debug更easy,但Jupyter Notebook用起来更简单
2. 数据的基本情况了解:pandas、numpy
numpy的处理速度快一点NumPynumpy.org/ 但Jupyter Notebook+pandas优雅、清秀的可视化界面显然更适合大多数人,基本能满足需求pandas - Python Data Analysis Library (pydata.org)pandas.pydata.org/
但Jupyter Notebook+pandas优雅、清秀的可视化界面显然更适合大多数人,基本能满足需求pandas - Python Data Analysis Library (pydata.org)pandas.pydata.org/
3. 数据可视化:Matplotlib,Seaborn
单变量分析-Matplotlib:可操作性更大
https://matplotlib.org/matplotlib.org/
多变量分析-Seaborn: Matplotlib的高级版
seaborn: statistical data visualization — seaborn 0.11.2 documentation (pydata.org)seaborn.pydata.org/
四、非常适合入门的项目
liulu1Q84/Data-Visualization: Data Visualization with Python (github.com)github.com/liulu1Q84/Data-Visualization