







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
描述数据分析业务(数据分析工作内容描述简历)
 2023-05-25
2023-05-25 浏览次数:次
浏览次数:次 返回列表
返回列表1. 描述数据常用的4个指标
(1)平均值
数据的总和除以数据的个数,即 μ= Σx/n\Sigma x/n 。
缺点:对异常数据不敏感。eg:一组工资数据{5k,6k,8k,10k,300k},被平均的工资。
(2)四分位数
先按升序排列数据(最小值为下界,最大值为上界),将数据分成四等份。四分位数是处于每个分割位置的数值。
中位数Q2:位于中央的数值。假设有n个数,如果n是奇数,中位数是位于中间数值;如果n是偶数,中位数就是中间两个数的平均值。
下四分位数Q1:最小分割数值。求下四分位数的位置,先计算n÷4,如果为整数,则位于n÷4这个位置和下一个位置的中间,取这两个位置上的数值的平均值;如果n÷4不是整数,则向上取整的结果为下四分位数的位置。
上四分位数Q3:最大分割数值。求上四分位数的位置,先计算3n÷4,如果为整数,则位于3n÷4这个位置和下一个位置的中间,取这两个位置上的数值的平均值;如果3n÷4不是整数,则向上取整的结果为上四分位数的位置。应用:
箱线图,比较不同数据集的整体情况。识别出可能的异常值。Tukeys test ,即最小估计值:Q1-K(Q3-Q1);最大估计值:Q3+K(Q3-Q1);K=1.5 中度异常;K=3 极度异常。(3)标准差
衡量数据的波动大小,即离散程度。标准差越大,数据波动越大,反之则越小。
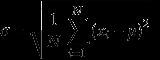
标准差的单位与相应计算数据的单位相同。
衡量标准差大小的好坏,取决于我们用标准差做什么事情。如选球员会优先考虑标准差小的,因为发挥稳定。
缺点:如果两个数据差别比较大,无法比较。eg:店铺A 销售额1000万,店铺B 销售额100万,两个店铺的标准差都是20万,若说两个店铺的波动幅度相同,这是不对的。
变异系数:标准差除以平均值得到的值。它可以消除数据大小的差异,所以通常用变异系数来比较不同数据集的波动大小。
(4)标准分
距离平均值多少个标准差。如果标准分等于0,表示等于平均值;小于0,表示小于平均值;大于0,表示大于平均值。
2. 数据集
2.1 数据字段含义
(1) 购买商品表
user_id:用户ID,一个用户一个ID
item_id:商品编号,识别对应的商品
cat1:商品种类ID,一级分类
cat_id:商品种类ID,二级分类
说明:商品一级分类和商品二级分类有联动关系,比如童鞋和拖鞋,童装和裤子的关系。
property:商品属性,属性值可以是大小、颜色、尺码等一切可以描述商品特征的。
buy_mount:购买数量
day:购买时间
(2) 婴儿信息表
user_id:用户ID,可以与表1关联的字段
birthday:出生日期,结合表1的购买时间计算得出年龄
gender:性别,0 女性,1 男性,3 未知性别
2.2 业务分析
(1)产品角度
根据时间、购买量、商品一二级类别,得出销量前10的商品类别根据购买量、商品一二级类别、商品编号,分析产品与商品类别的销量情况(可以带上时间)(2)用户角度
从不同性别分析产品的购买量从不同年龄阶段分析产品购买情况