







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
读完本文你就了解什么是文本数据分析(文本分析数据集)
 2023-05-17
2023-05-17 浏览次数:次
浏览次数:次 返回列表
返回列表“ 信息时代,一切皆是数据。”
本文主要介绍文本数据分析方法和常用场景。
01
—
文本分析概述
日常大家泛指的数据分析仅仅是数字数据的分析,其实数据不仅仅包括数字数据,还有文本数据,图片数据, 音频数据,视频数据。只不过这些数据在计算机里面存储都是二进制的01 编码。

但是在感官上来说,这几种数据还是有区别的。最大的区别在于,数字数据更容易结构化。做透视和可视化比较容易,而其他几种数据只有在特殊的场景下才会用到,而且会有繁琐的数据清洗,数据特征提取工作,日常工作中的商品文本评论数据就很普遍了,如何挖掘评论里面的信息就用到了文本分析的思路。作为一名数据小匠接下来几篇文章就给大家介绍一下文本分析的框架和案例。
什么是文本分析
文本分析顾名思义就是对文本数据进行分析。从文本中对特征进行挖掘以及特征进行统计分析。
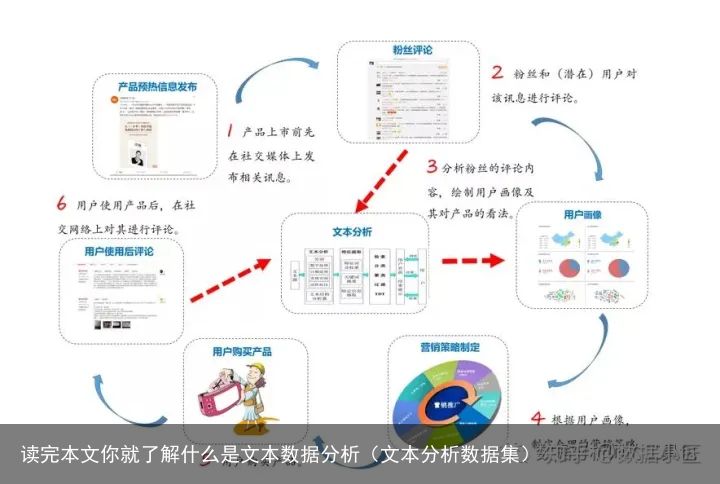
那么先来了解下什么是文本,文本有哪些特征。
什么是文本
文本,是指书面语言的表现形式,从文学角度说,通常是具有完整、系统含义(Message)的一个句子或多个句子的组合。一个文本可以是一个句子(Sentence)、一个段落(Paragraph)或者一个篇章(Discourse)。
文本的结构以中文为例:单字 可以组词语,词语可以造句,句子组成段落,段落构成文章。层层递进。
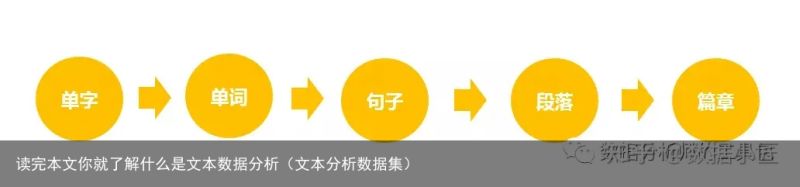
希腊语系和亚洲语系的区别亚洲语系(中日韩):字 词 句 段落 篇章希腊语系(德法希西拉):词 句 段落 篇章
中文:掌握工具,思维,业务知识的人才是可能成为优秀的数据分析师英文:Talents with tools, thinking, and business knowledge are likely to become excellent data analysts日文:ツール、思考、ビジネス知識を備えた才能は、優れたデータアナリストになる可能性があります韩文:도구, 사고 및 비즈니스 지식을 갖춘 인재는 우수한 데이터 분석가가 될 가능성이 높습니다.法文:Les talents dotés doutils, de réflexion et de connaissances commerciales sont susceptibles de devenir dexcellents analystes de données
你会发现希腊语系 没有字的概念,这是为什么学英语叫背单词,学中文叫背生字。中文是比英语难的原因就是:中文由生字 组词 然后再根据语法造句。而英文呢?直接由生词根据语法进行造句。英文每个单词之间有空格分开,中文则没有,而是每个字紧密组合在一起的。而且字字组合,就组合成无数的词语。所以中文要达到和英文一样就需要分词了,这也就引出了后面的"中文分词"了
文本分析的主要路径
以英文为例,先将句子按照空格将单词分成一个一个的单词,然后再按照某种计量方法(词频,TF_IDF ,word2vec) 将文本数据转化为词向量,词矩阵的数字数据.转化为词向量了,词矩阵就是数字数据了,后面的分析方法和数字数据的分析方法大同小异了(文本语义除外)。
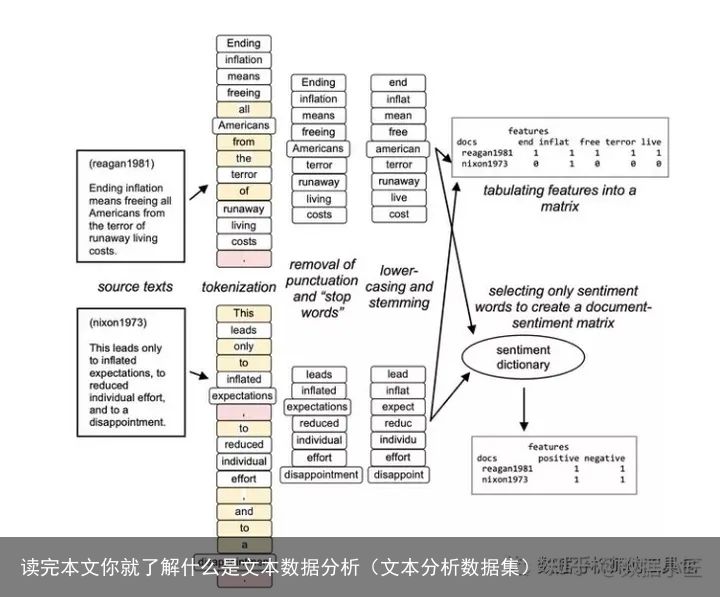
中文的不同之处
中文句子之间没有空格,很难进行分割,需要按照组词的方式进行分割。这也就引出了 中文分词了。
例如:中国人民万岁(句子) -----> 中国 人民 万岁(3个词语)
分词常用的方法:
正向最大匹配法(由左到右的方向);逆向最大匹配法(由右到左的方向);最少切分(使每一句中切出的词数最小);双向最大匹配法(进行由左到右、由右到左两次扫描)分词常用的算法包:
word分词 SCWSFudanNLPCC-CEDICTMMSEG4J盘古分词结巴分词02
—
文本分析的场景
文本分析如果从智能的维度来分类可以分为以下三大类:
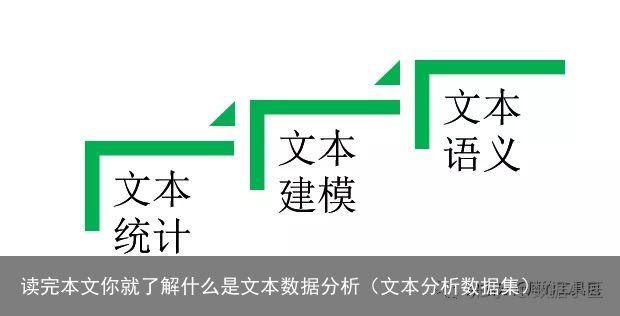
第一类:文本统计分析(根据规则统计文本)
这一阶段,主要是对文本中出现的 词语进行统计分析,运用场景主要有:
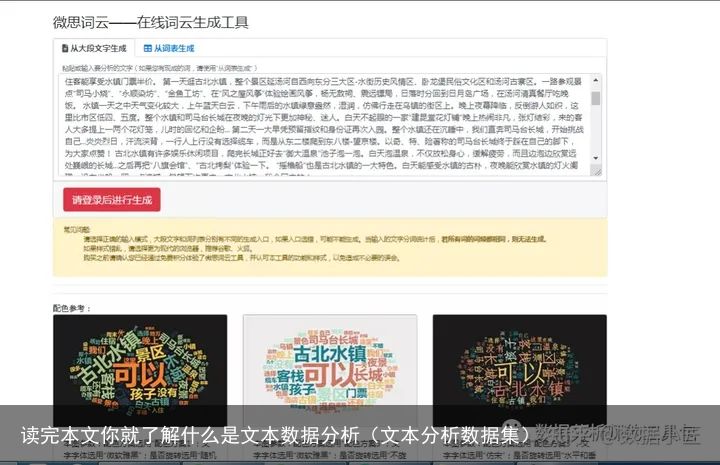
1 词云 词频 https://wis-ai.com/wordcloud
词频是对文章中的单词进行频数统计,然后根据频数来度量大小,画成词云图。例如一篇介绍旅游的文章,通过词频可以快速的知道旅游景点的特色。如下图:
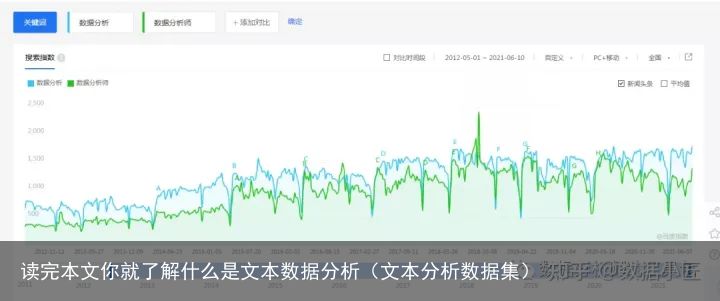
2 舆情分析 百度指数: https://index.baidu.com/v2/index.html#/
简单的舆情分析,就是统计某个特定的单词在不同时间出现的频率,根据频率做出某种判断。举个例子,大家搜索数据分析这个关键字,根据数据分析出现的频率来判断国民对数据分析的热度。当然你还可以用其他的词来监测你想做的判断。比如:某家抖音,他就监控快手 来达到竞对分析的目的。
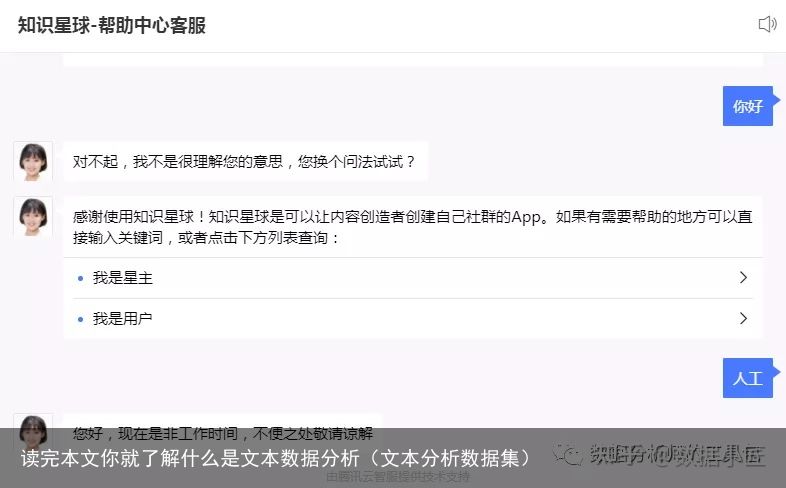
3 简易版的智能客服
简易版的智能客服就是这种模式,当你直接输入“人工”,他就知道 机器人不能回答你的问题,很快就帮你转接人工了。这个技术含量不高,但是特别实用,因为一般高频的问题回答,也可以这么设置。当然那些真正智能的客服就涉及到语义分析了,后面再讨论。
第二类:文本建模分析(根据模型监督鉴别文本)文本建模是通过将文本进行数字数据化之后,再和机器学习等算法进行结合
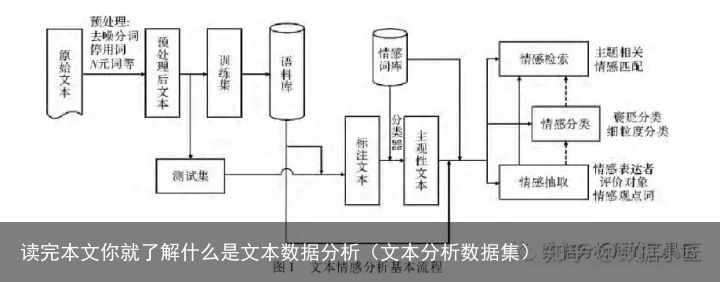
1 情感分析(情感分类=文本量化+分类算法)
现在很多电商公司都会有产品反馈的一些评论数据,这些评论数据有的是积极满意的,有的是消极不满意的。公司一般需要随时监控这些消极的负向反馈,以便改进产品质量和运营策略。
例如:某产品有很多评论文本,可以根据这些评论文本进行机器学习,然后根据训练的模型快速识别新进来的评论是消极还是积极。
2 词语网路分析
例如:下面这些 人名词语可以通过节点连起来,最后可以表达词语之间的关联性,包括时空关系和亲密度关系。

第三类:文本语义分析(根据语法读懂文本的意思)文本语义分析这里会采取深度学习等复杂算法进行训练,使得可以从文本中挖掘出来具有语法信息的文本信息。
1 主题模型LDA
主题模型(topic model)是以非监督学习的方式对文集的隐含语义结构(latent semantic structure)进行聚类(clustering)的统计模型。主题模型主要被用于自然语言处理(Natural language processing)中的语义分析(semantic analysis)和文本挖掘(text mining)问题,例如按主题对文本进行收集、分类和降维;也被用于生物信息学(bioinfomatics)研究 。隐含狄利克雷分布Latent Dirichlet Allocation, LDA)是常见的主题模型
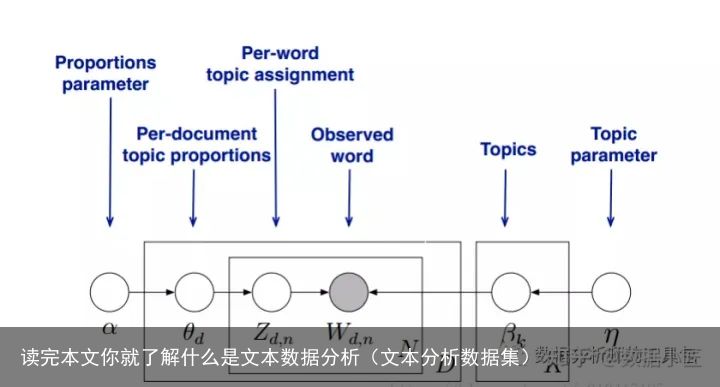
例如:我将100篇不知道的什么内容的文章扔进模型,最后输出四个主题,每个主题还给出了关键的词语,可以大致概括文本内容

2 word2vec字面意思:即Word to Vector,由词到向量的方法。专业解释:Word2Vec使用一层神经网络将one-hot(独热编码)形式的词向量映射到分布式形式的词向量。使用了Hierarchical softmax, negative sampling等技巧进行训练速度上的优化1。作用:我们日常生活中使用的自然语言不能够直接被计算机所理解,当我们需要对这些自然语言进行处理时,就需要使用特定的手段对其进行分析或预处理。使用one-hot编码形式对文字进行处理可以得到词向量,但是,由于对文字进行唯一编号进行分析的方式存在数据稀疏的问题,Word2Vec能够解决这一问题,实现word embedding(个人理解为:某文本中词汇的关联关系 例如:北京-中国,伦敦-英国)。最主要的用途:一是作为其他复杂的神经网络模型的初始化(预处理);二是把词与词之间的相似度用作某个模型的特征(分析)。
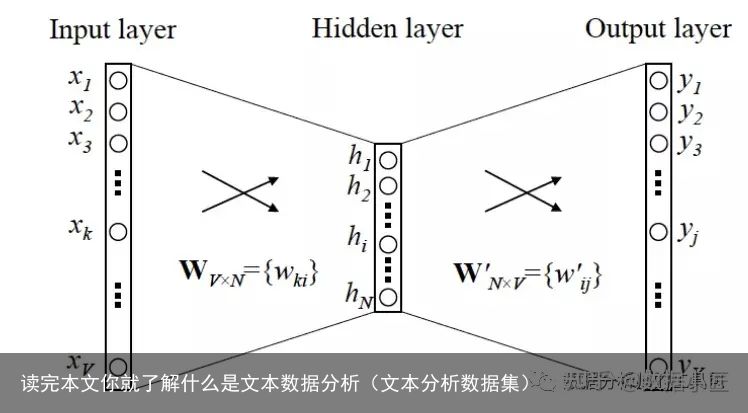
例如:大家说"苹果"到底是指水果呢,还是指苹果手机呢,就可以根据word转化的向量来求两个词语的相关性,
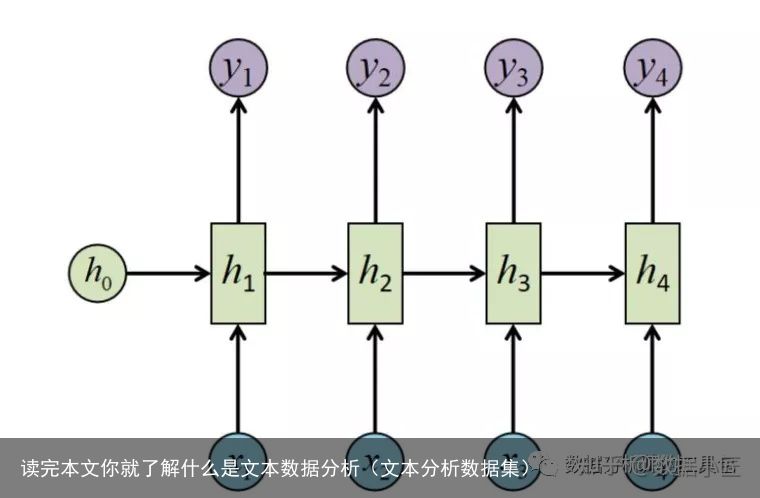
3 RNN或LSTM
人机智能对话了,不同语言之间的翻译都用到了这些深度学习相关的内容,这里就不做介绍了,水平有限。大家可以延展阅读。
03
—
总结
人人都是数据分析师的时代,对专业的数据分析师要求越来越高,所以你需要积累更多的专业知识和业务知识去面对充满挑战的明天,接下来的几篇会继续分享上述提到的分析方法和思路的具体案例。
欢迎大家与我交流,微信:suancaiyu201 公众号:数据分析师的工具包
