







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据分析具体案例(数据分析具体案例有哪些)
 2023-05-15
2023-05-15 浏览次数:次
浏览次数:次 返回列表
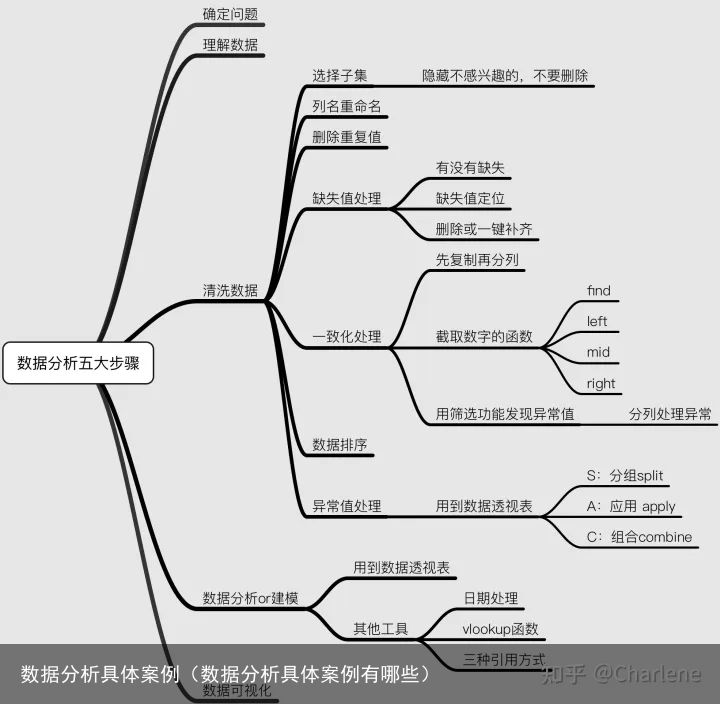
返回列表数据分析一共有五大步骤:
明确问题:想从数据里面获得什么信息,分析什么问题;理解数据:理解数据横、列,代表的信息是什么。数据清洗:目的是保留必要的信息,或者将信息的格式规范统一,便于分析。一般占到数据分析总时间的60%。数据分析or构建模型:数据可视化:用一张思维导图展现今天的分享框架~
以母婴行业电商销售数据为例
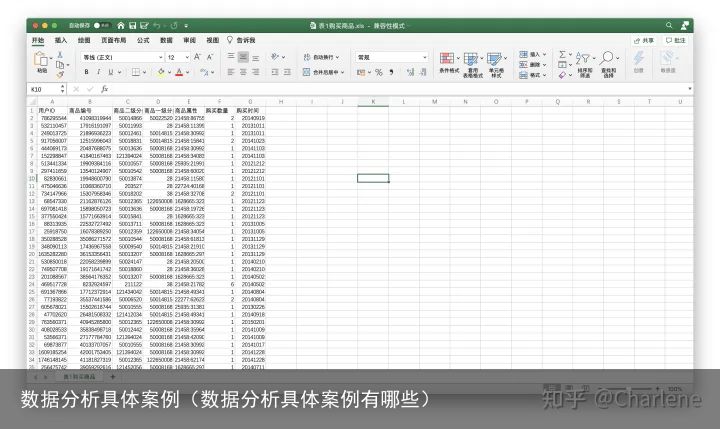 原始数据清洗之前
原始数据清洗之前一、明确问题:
总体来看,那种商品的销量最高?卖得最好的是哪一种规格/属性?
不同年龄段的婴儿的购买偏好(各个不同年龄段不同商品的销量排名)
不同性别婴儿的购买偏好(不同性别的婴儿不同商品的销量排名)
不同年龄段不同性别的婴儿的销量排名
不同季节的购买偏好 (不同季节的商品销量排名)
销售量如何随着时间变化(年、季度、月的销售额如何变化)
每个用户的购买记录
一级分类的商品中那一类商品卖得最好?
各个一级分类下,哪种二级分类的商品卖得最好?
二、理解数据:
看行、列,分别有什么信息
 列名先全选之后自动换行,让被因为太长被遮住的内容显示出来
列名先全选之后自动换行,让被因为太长被遮住的内容显示出来三、清洗数据、
1、选择子集:确定感兴趣要分析的几个列
比如这里商品属性我就可以隐藏了
隐藏:右击选中的单元格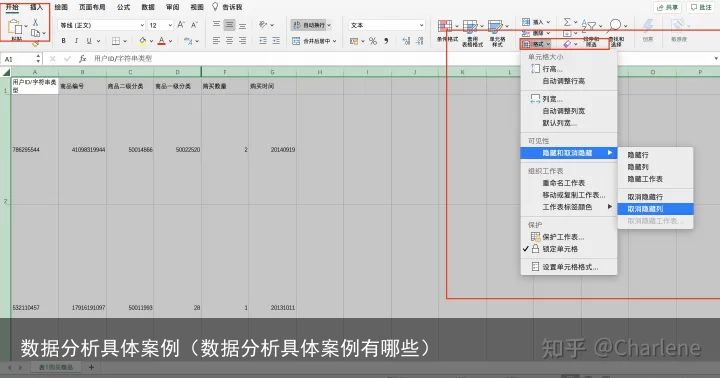 取消隐藏:开始-格式-隐藏与取消隐藏
取消隐藏:开始-格式-隐藏与取消隐藏2、列名重命名:换成自己喜欢喜好的。比如中换英。
这里没有什么需要重命名的
3、删除重复值
这个地方不需要进行重复值处理,因为可能同一个用户买了不同的商品。
但是还是示范一下如何删除重复项
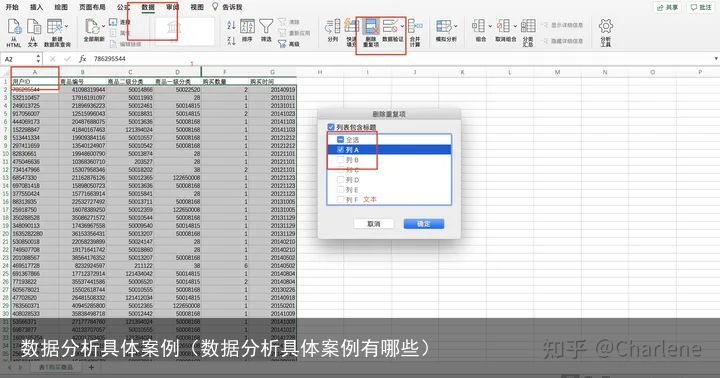 删除重复值:数据-删除重复项-取消全选-选择哪些列是要删除重复项的
删除重复值:数据-删除重复项-取消全选-选择哪些列是要删除重复项的点击确认之后就是这样的界面
可能同一个用户ID买了不同的商品,所以我要把它们恢复,直接撤销刚刚的操作就可以了。
4、缺失值处理:有没有缺失-定位缺失-一键补全
首先知道有没有缺失值
把鼠标在每一列最上面点一点,看看右下角的“计数”,就知道有没有缺失值了。
 在每一列上面点一下
在每一列上面点一下 同时依次看下下面的计数,就知道有没有缺失了
同时依次看下下面的计数,就知道有没有缺失了如何定位呢?
 定位:开始-查找-定位条件
定位:开始-查找-定位条件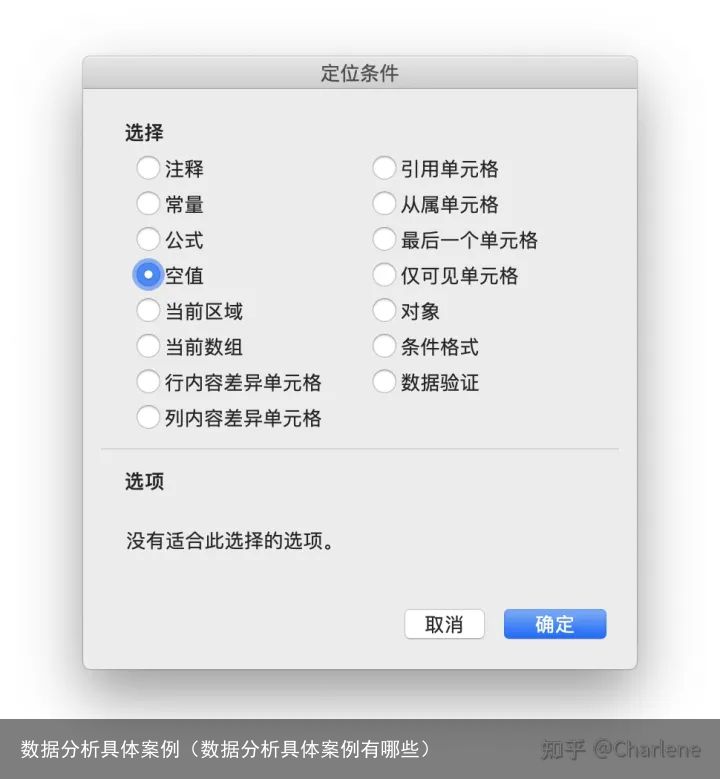 选择“空值”
选择“空值”点击确认之后,就会定位空白的地方
一次性补全
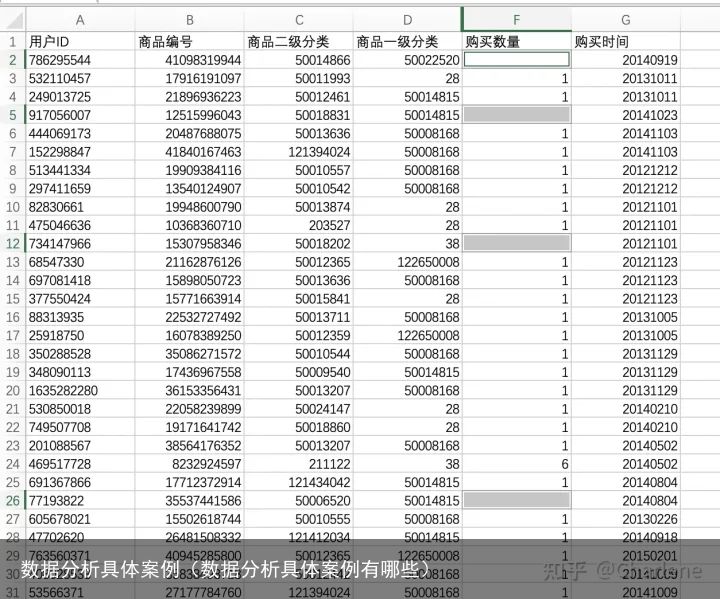 输入2,完成后同时按住ctrl+enter,其他空白就都变成2
输入2,完成后同时按住ctrl+enter,其他空白就都变成2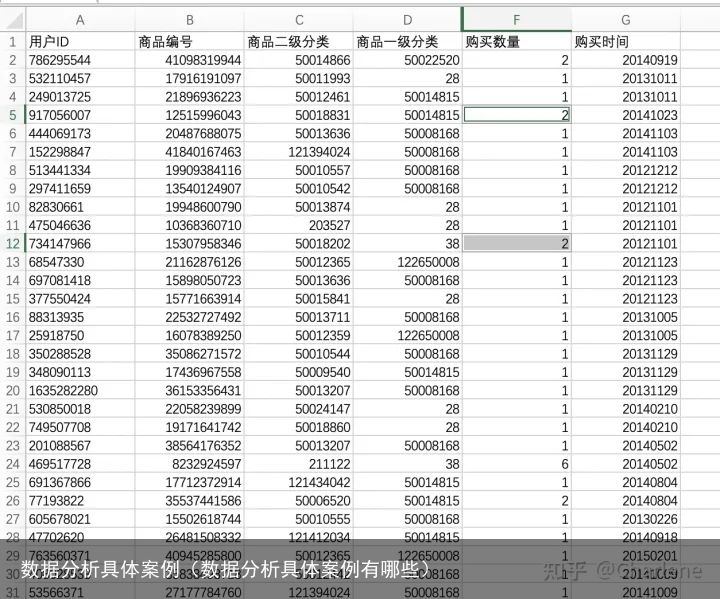
5、一致化处理:使用分列功能
这里用另一个招聘网站的例子

比如这个公司所属领域有逗号,就可以把它分割开
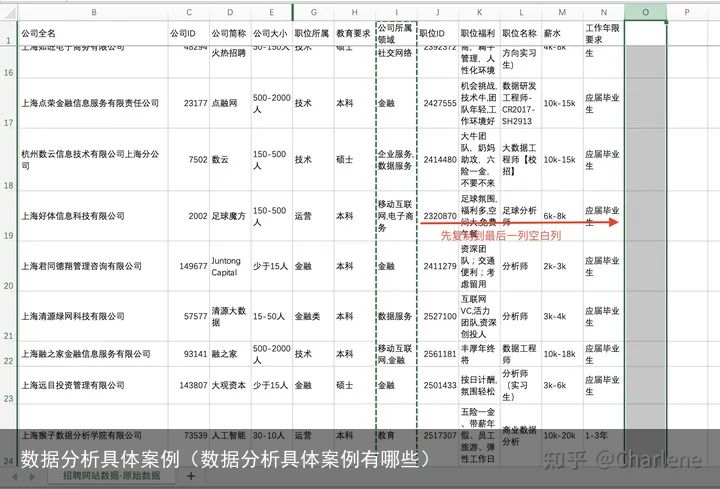 复制这一列到最空一列空白列
复制这一列到最空一列空白列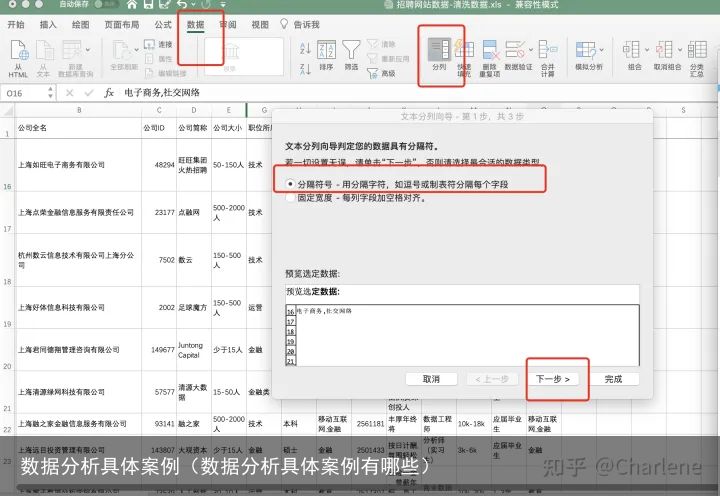 数据-分列
数据-分列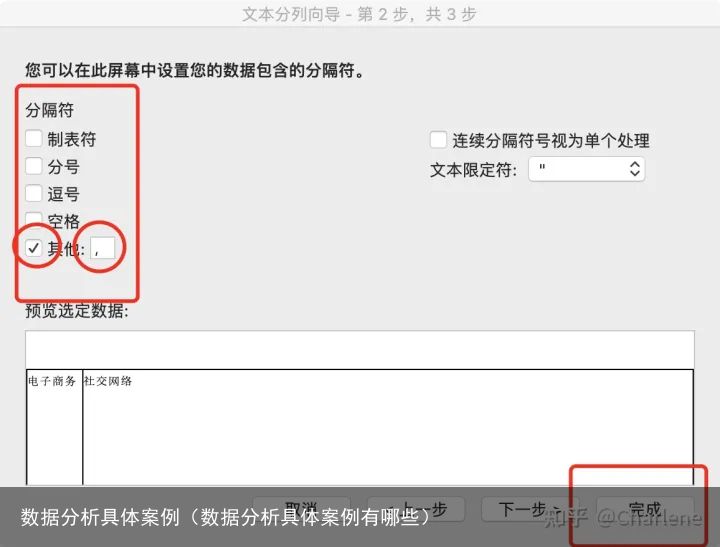 自己在“其他”里输入分列标准
自己在“其他”里输入分列标准补充说一下Excel常用的一些函数。
什么是函数呢?函数是一个工具。把函数想像成榨汁机就行了。不用知道原理,只要知道扔进去水果,会有果汁出来。同样,函数就是,扔进去一些数据,出来想要的数据。
先说平均数。还是以招聘网站的信息为例。
比如薪水有个范围,我们就把它设置成最低薪水和最高薪水,然后在最低薪水和最高薪水之间算一个平均数。
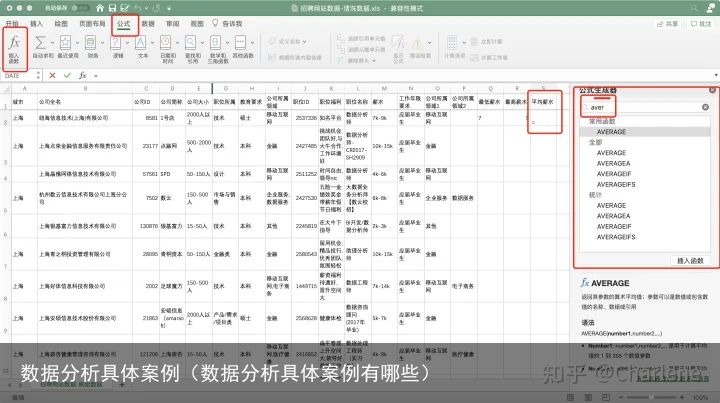 插入函数的步骤
插入函数的步骤点击空白单元格-公式-插入函数-直接检索需要的函数-插入,然后根据提示在函数的参数位置输入数据,如下图。
但是每一个都这样输入非常麻烦,怎么办呢?
两个办法,第一个办法是使用分列,分列标准是xK-xK中间的“-”,然后再用“k“为分列标准再分一次。具体分列方法如上。就可以得到这样的数据界面。
下面说第二种方法,用查找和截取字段的函数把数字单独分离粗来。
用find函数,查找一个字符串在另一个字符串中的位置。比如,在7k-9k中,第一个k的位置就是2。
下面几个函数经常和find函数一起使用完成字符串截取的工作。所以肯定会用到函数的嵌套了。
left函数:=LEFT(字符串所在单元格位置,从左开始 到XX位置进行截取)。如=LEFT(M2,2)
(“XX位置”是某一个数,同时包括了XX位置的内容。所以有的地方需要-1)
(比如这里2就是这个“XX位置”,怎么得来的呢?用find函数嵌套进left函数)
(所以k也被算进去了,所以我要在find函数后面-1)。不理解也没关系,一步步来,先不-1,试一下就知道k会被截进去。
这里的find是刚刚写好的,现在可以直接用,在前面写left就行。
right函数:=RIGHT(字符串所在单元格位置,从右开始到XX位置进行截取)。如RIGHT(M2,2)
mid函数:=MID(字符串所在单元格位置,开始位置,截取长度)。如
开始位置,是中间的-,用find查找。嵌套进mid中。
-的位置:FIND("-",M2)
因为数字在后一位,所以+1,FIND("-",M2)+1。开始位置是FIND("-",M2)+1。
截取长度比较复杂。要用整个字符串的长度,减去-所在的长度。剩下绿色的部分。现在只要保留数字,所以还要-1。长度是len(M2)-FIND("-",M2)-1。
最后得到最高薪水的数字如下
个人觉得,还是分列比较好用一点呢。函数脑子不太容易转。当然可以实践一下。
自动填充不用说了,鼠标放在单元格右下角,出现黑色十字架之后,然后按住鼠标,把那个十字架往下拖。
做到这里没有结束,要看一下有没有什么异常值。用筛选功能。拉到最下面。
会发现这里有异常值,是因为有的薪水项,k是用大写K表示的。一起替换一下就行了。
数据清洗可能不是一次性的,可能不同的环节会进行多次。
这种形式的错误这么处理呢?点击一个这样的单元格,然后会发现是字符串,而不是数字。怎么处理呢?
先复制数值。一定是选择性粘贴。
在进行分列处理
然后会发现复制之后单元格的绿色图标(标注是字符串)没了。
把复制之前的隐藏掉就行了。
然后再计算一次平均数~
6、数据排序
这就不用多说了吧。
7、异常值处理:需要用到数据透视表的功能
数据透视表的原理(SAC):按照一定的属性将数据进行分组(split)、应用函数(apply)、对上一步函数的计算结果进行汇总组合(combine)
如何实现呢?
选中按照什么列名分组之后,拖到行标签这里再拖到列,表示把这一列中各个项目出现的次数进行计数这张图来说明如何处理异常值。
左边黄色框出来的,就是异常的,不涉及数据分析的工作。用到3个函数
首先用find函数,找出关于“数据分析师”字眼的,此时find函数中,参数是一个数组{"数据分析","数据运营","分析师"}。
然后会变成这样,
在用count函数计数,确定这个数组参数中的值出现了几次,
就把上面的第1、3个参数出现(出现两个参数)整合成次数2了。
最后用if确定,只要这个count的值不等于0,就是“是”
再往下拉几个,就可以全部判断是不是数据分析师的岗位了。
最后进行筛选就可以了,最后只剩下数据分析师的岗位~
数据清洗工作基本到这里就结束了~虽然有点麻烦,但是只要清洗好了,后期分析起来,完全不是问题。磨刀不误砍柴工。
四、数据分析
另外,按照上面的方法,还可以探寻其他问题的答案,比如在哪个城市找到数据分析师的机会可能更大?或者说那个城市对数据分析师的需求最大。
还想看看列这里按照工作年限有什么区别,那就把工作年限拖到列那里
可以看到1-3年和3-5年的工作年限,是需求最大的。
用列百分比的方式显示,出现的表格就是百分比显示的了~
怎么看平均工资呢?
先加载勾选一下分析工具
然后按照下图中的进行勾选设置命名~
得到这样的数据
最后看看不同城市的薪水平均值,需要用到数据透视表。行有城市,另外值的计算加上平均数就行。记得最后把值汇总依据调整成“平均数“,不然就会算成求和的。。。
最后得到这样的数据
再看看不同年限的平均薪水变化
可以看到还是越老越吃香的~
五、其他
接下来说明日期的处理问题
需要用到“数据-分列”功能,前两步都是一样的
但是到第三部的时候,需要勾选到“日期”,YMD的格式了
然后会发现有了统一的格式
如果不是一样的,右键单击选择设置单元格格式
在日期这里选择一种格式即可
接下来使用透视表按月或季度看数据
在日期这一列右键单击选择“组合”就可以出现这样的界面,选择月、季度、年,就可以按这个分组看数据了
如何按周汇总数据呢?
也是在组合对话框中设置
接下来就是按周汇总的数据
和上述分析平均数的方法一样,在值字段汇总这里,把“求和”设置成“最大值,就能看到每个月的最大销售量
再来说说vlookup函数
(找什么、在哪找、第几列、准确找还是近似找)
点击插入函数之后,就会出现四个空格,分别对应
在哪找第几列精确找是0,近似找是1。
最后出现这样的结果
那如何查找重复值呢?
第一个方法添加辅助列,找什么的时候,点击“辅助列”对应的单元格
如何用vlookup对数据进行分组?
先要确定一个分组,也就是查找范围
区分三种引用:
相对引用:A1;。拖动的时候,引用的也会跟着拖动 。A1,F4按四次
绝对引用:$A$1 (按住f4可以实现)。不管怎么拖动,引动的那一个单元格都不动。$A$1,F4按一次。
混合引用:$A1 或 A$1 。行或列不动。谁前面有$美元符号,谁不动。 A$1,F4按两次;$A1,F4按三次。
下次分享数据可视化~嘻嘻
