







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
R语言 简单数据处理和分析(r语言数据分析案例报告)
 2023-11-27
2023-11-27 浏览次数:次
浏览次数:次 返回列表
返回列表目标数据:朝阳医院2016年销售数据.xlsx
对该excel销售数据进行处理完成业务指标任务
业务指标主要有:
月均消费次数
月均消费金额
客单价
消费趋势
数据导入
首先数据导入
将excel数据导入R中,常用XLConnect和openxlsx工具包。
#读取Excel数据 install.packages("openxlsx") library("openxlsx") readFilePath <-"D:/R/朝阳医院2016年销售数据.xlsx" exceldata <-read.xlsx(readFilePath,"Sheet1")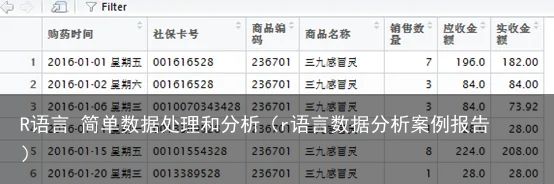
在完成业务指标之前,首要的任务是要准备好数据,对数据进行预处理,因为数据会出现不完整、不方便处理数据等问题。
一、数据预处理
数据预处理主要有以下步骤:
列名重命名
删除缺失数据
处理日期
数据类型转换
数据排序
1.列名重命名
把中文列名改成英文列名,方便后面数据处理
names(exceldata) c("time","cardNo","drugId","drugName","saleNumber","virtualMoney","actualMoney") #列名重命名
2.删除缺失数据
na.omit) ()删除所有含有缺失数据的行,is.na()检测是否有缺失值
exceldata <- exceldata[!is.na(exceldata$time),] #删除time列缺失值3.日期处理
在表中time列的时间进行处理(剔除星期),首先拆分字符,再次选取需要的时间字符串
> #处理日期 > library("stringr") > timeSplit <- str_split_fixed(exceldata$time," ",n=2) > timeSplit [,1] [,2] [1,] "2016-01-01" "星期五" [2,] "2016-01-02" "星期六" [3,] "2016-01-06" "星期三" [4,] "2016-01-11" "星期一" [5,] "2016-01-15" "星期五"stringr包是用来处理字符串的。str_split_fixed: 字符串分割,同str_split,str_split_fixed(x,split,n),x:需要处理的字段/字符,split:用于分割的字符串,n:分隔为多少列。
exceldata$time <-timeSplit[,1]对时间处理结果
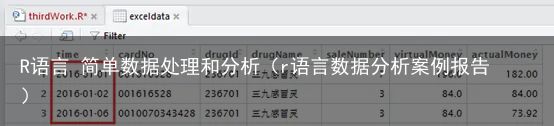
4数据类型转换
查看time字段类型为字符类型
> class(exceldata$time) #查看时间字段的类型 [1] "character"将字符类型转为时间类型
> exceldata$time <-as.Date(exceldata$time,"Y%-m%-d%") > class(exceldata$time) [1] "Date"对金额和数量转化为数值类型,方便后面业务指标数值计算
exceldata$saleNumber <-as.numeric(exceldata$saleNumber) #销售数量 exceldata$virtualMoney <-as.numeric(exceldata$virtualMoney) #应收金额 exceldata$actualMoney <-as.numeric(exceldata$actualMoney) #实收金额5.数据排序 order()
按销售时间对数据进行降序排序
exceldata <-exceldata[order(exceldata$time,decreasing = FALSE),]结果让我出乎意料,time列时间全部变成NA,记录的时间不见了,运行多次还是这样的结果。

往回寻找出现问题的地方,一步步的运行寻找原因,在时间转换的时候就出现变成NA的问题。网上搜索找不到答案,弄了半个小时没有找到问题所在。

把问题放在一边,只好翻书看时间转换知识,写代码运行时候,结果发现问题所在,是自己记错了时间转换的代码,把正确的Y-%m-%d写成Y%-m%-d%,出现运行错误,time列变成NA

修改时间转换代码之后得出正确的时间排序结果,而不会发生time列变成NA情况,按销售时间对数据进行降序排序
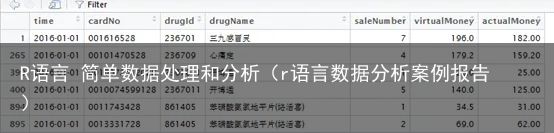
数据的预处理工作基本上完成了,接下来要完成业务指标
二、业务指标分析
指标1:月均消费次数
月均消费次数=总消费次数 / 月份数
同一天内,同一个人发生的所有消费算作一次消费
用duplicated去掉同一天同一个人的重复消费记录,在计算总的消费次数当中将每个人每天的不同消费记录作为消费一次
kpi1 <- exceldata[!duplicated(exceldata[,c("time","cardNo")]),] #删除社保卡和时间相同的行计算总消费次数(总行数)
consumeNumber <- nrow(kpi1) #总消费次数 > kpi1 <- exceldata[!duplicated(exceldata[,c("time","cardNo")]),] #删除社保卡和时间相同的行 > consumeNumber <- nrow(kpi1) #总消费次数 > consumeNumber [1] 5398得出总消费次数是:5398次
计算总月份数,第一行时间与结尾时间之差除以30取整
> #月份数 > startTime <- kpi1$time[1] #最小时间值 > endTime <- kpi1$time[nrow(kpi1)] #最大时间值 > #月均消费次数 > day <- endTime - startTime #天数 > month <- day %/% 30 #月份数 Error in Ops.difftime(day, 30) : %/%对"difftime"对象不适用 > day <- as.numeric(day) #转为数值型 > month <- day %/% 30 #月份数 > month [1] 6得出总月份数是:6个月
计算月均消费次数
> #月均消费次数 > monthConsume <- consumeNumber / month > monthConsume [1] 899.6667月均消费次数:899次
指标2:月均消费金额
月均消费金额,顾名思义,就是总消费金额除以月份数
> #总消费金额 > totalMoney <- sum(exceldata$actualMoney,na.rm = TRUE) > monthMoney = totalMoney / month > monthMoney [1] 50771.71月均消费金额:50771.71元
其中,sum()函数的na.rm参数设置为TURE,在计算总金额时去除缺失的数据
指标3:客单价
> #客单价 > pct <- totalMoney / consumeNumber > pct [1] 56.43391客单价:56.43391元
指标4:消费趋势
计算每周的消费金额:
要用到分组函数tapply()
> #每周的消费金额 > week <- tapply(exceldata$actualMoney,format(exceldata$time, "%Y-%U"),sum) > week 2016-00 2016-01 2016-02 2016-03 2016-04 2016-05 2016-06 2016-07 2016-08 2016-09 2016-10 2016-11 2016-12 1972.80 9679.64 10979.01 8719.73 15662.30 18758.82 3665.70 8441.51 8453.57 9988.98 8500.78 9869.16 10135.23 2016-13 2016-14 2016-15 2016-16 2016-17 2016-18 2016-19 2016-20 2016-21 2016-22 2016-23 2016-24 2016-25 8426.46 11400.66 14408.21 10385.33 10265.98 9496.06 9728.40 11794.11 11497.20 9530.38 10806.71 11877.43 14077.38 2016-26 2016-27 2016-28 2016-29 10894.90 8386.97 13372.67 3454.18绘制曲线图
week <-as.data.frame.table(week) #将数据转为数据框 names(week) <- c("time","actualMoney") #修改列名 week$time <- as.character(week$time) #转换为字符型 week$timeNumber <- c(1:nrow(week)) #绘制曲线图,用plot()函数 plot(week$timeNumber,week$actualMoney, xlab = "时间(年份-第几周)", #x轴标签 ylab = "消费金额", #y轴标签 xaxt = "n", #禁用X轴 main = "2016年朝阳医院消费曲线", #标题 col = "green", #绘图颜色绿色 type = "b") axis(1,at = week$timeNumber,labels = week$time,cex.axis = 1.5) #绘制坐标抽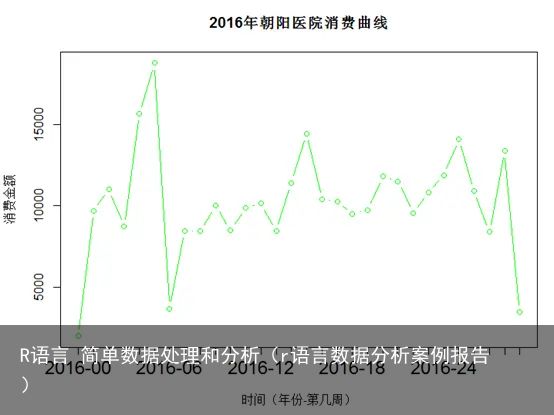
总结
通过实例练习把《R语言实战》第三、四章内容的基础知识运用上,加深了理解,是一种很好的复习形式,在操作过程中出现多次错误,在错误中寻找问题,从而解决问题,可提高自己的解决问题能力,比如代码变量名少写或者遗漏、大小写字母、中英文符号、时间转换方式、数据类型转换以及数据包导入等问题。让我知道解决遇到的错误正是学习的一种方式,学是为了用才有用,确实多实践才有进步,实践可以检验对错,也可以提高解决问题能力。希望一样爱好R语言学习的伙伴多实践,每天进步。
