







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
组学方法与数据分析-R语言(高阶篇一)(r语言各种分布)
 2023-11-26
2023-11-26 浏览次数:次
浏览次数:次 返回列表
返回列表在之前R语言的基础篇和进阶篇中,我们分别简单介绍了R和RStudio的下载及安装,并用R中的4行代码绘制了热图。然而这些只是R的入门,R所涉及的广度和深度令人叹为观止。相信很多小伙伴们对近几年来高分杂志上的图片越来越陌生。以往我们看到CNS正刊和重要子刊上的western blot条带,免疫荧光结果,可能只会感慨:要是我(们)有这些转基因小鼠,这些高大上的光学成像设备“没准”也能做出这些漂亮的成果(如图1所示)。然而现在面对高通量测序下的大数据,看到这些花花绿绿的热图(heatmap)、火山图(volcano plot),PCA,t-SNE分析(如图2所示)却感到手足无措,毫无头绪(既看不懂,也不会做)。究竟是什么把我们的研究成果阻挡在高分杂志门外?这是多因素杂糅的结果,非直言片语就能说清,也不是我们本期内容的重点。但是却发人深思:“我们是否需要紧跟这些热点,才能不被甩远?”
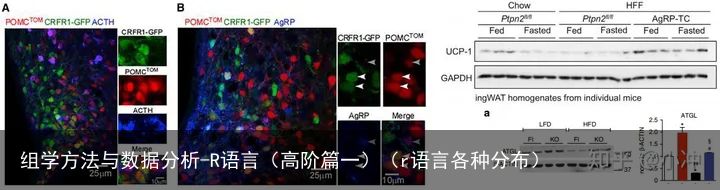 图1 很漂亮的免疫荧光染色结果和WB结果
图1 很漂亮的免疫荧光染色结果和WB结果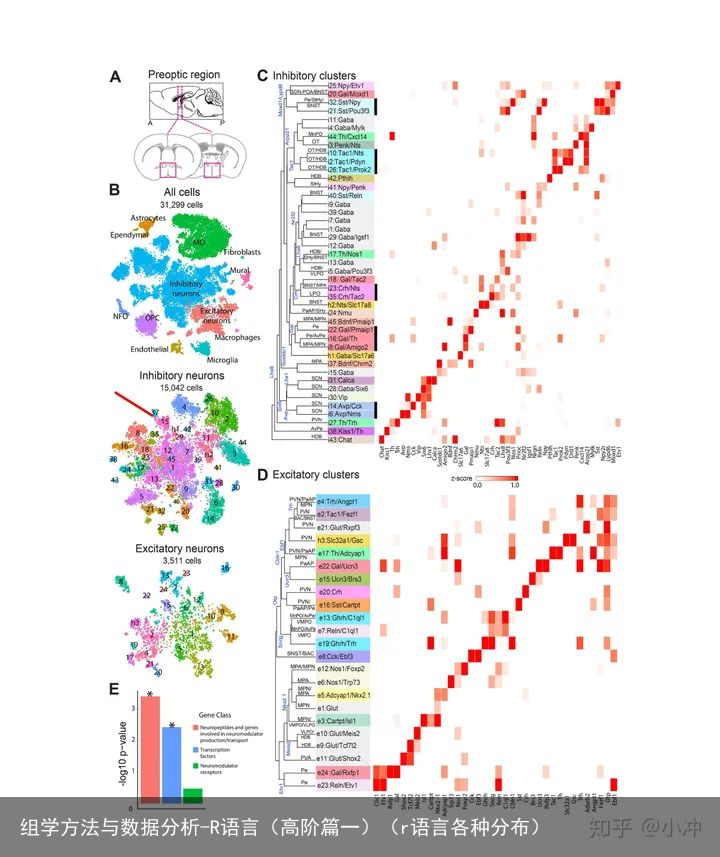 图2 “看不懂”的t-SNE和聚类分析
图2 “看不懂”的t-SNE和聚类分析有人觉得没必要追热点,认为学者蹭学术热点无异于哗众取宠。也有人觉得当年火极一时的meta分析这些年不也渐渐式微,甚至好多学校不再将这些文章纳入晋级评奖的标准?有人觉得生信分析/数据挖掘只是“噱头”,又能挖出多少真正有价值的东西?事实上,这些想法不能说全无道理,但是有点片面。诚然,数据挖掘只是一个方法和手段,挖到的信息是“黄金”还是“垃圾”都有可能,后续还需要低通量下的实验验证。因此,没有必要将数据挖掘和实验操作完全割裂开来。二者本就是相辅相成,一个负责预测,一个负责验证。离开了预测直接验证或者离开了验证只预测都不错,只是不那么完整罢了。
啰啰嗦嗦了很多,为什么要学R语言呢?尽管热图、火山图可以用GraphPad绘制,然而聚类分析/PCA/t-SNE等分析无法用GraphPad完成。且GraphPad的绘图和数据分析均比较适合于低通量实验下数据量少的情况。对于高通量数据还是建议使用R语言(或者Python),会更方便些。而且很多东西都是相通的,比如当我在PS中学会“ctrl+z”是撤销后,很快发现PDF中、word中都可以使用“ctrl+z”来撤销上一步操作。同样地,当你学会R的基本操作后,之前在Excel里很多搞不定的操作(比如借助vlookup函数做高级查找等)均可在R中轻松解决(以后即使从事办公室工作,也是Excel大佬)。
由于我们大部分人不做R包的开发工作,而只是作为链条下游的应用者,因此,了解各个函数包的用法,copy别人的代码并适当修改做到为我所用即可。遇到看不懂的代码可以借助help功能(?function)来探索,遇到代码报错时不要慌,仔细检查后还有问题的话可以将报错信息复制至搜索引擎检索,一般会看到代码大神给出的建议。

当然,作为医学口或者生物学口的我们,每天用少量业余时间跑点代码即可,没必要投入太多精力,除非是主做生物信息学分析的人员可以花大力气研究。精力充沛者可以尝试阅读R语言相关书籍,比如《R in action》,目前是第二版,或者是《Advanced R》,跑跑代码的同时还可以顺便学学英语。当然,考虑到R和RStudio多安装在C盘,且后期需要处理大数据,因此建议入手一台配置性能(特别是处理器)较好的电脑。
 华为MateBook D14 ,i7处理器跑起R语言轻轻松松!!!京东¥6499.00去购买
华为MateBook D14 ,i7处理器跑起R语言轻轻松松!!!京东¥6499.00去购买
由于生信分析中用到的部分函数包对拟处理的数据格式有明确要求,因此为了后面抄(划掉)写代码时减少报错的机率,我们先来了解下常见的数据类型。R常处理的数据对象包括:向量(Vector),矩阵(Matrix),数组(Array),数据框(Data frame)和列表(list)。这些数据类型的区别如图3所示。
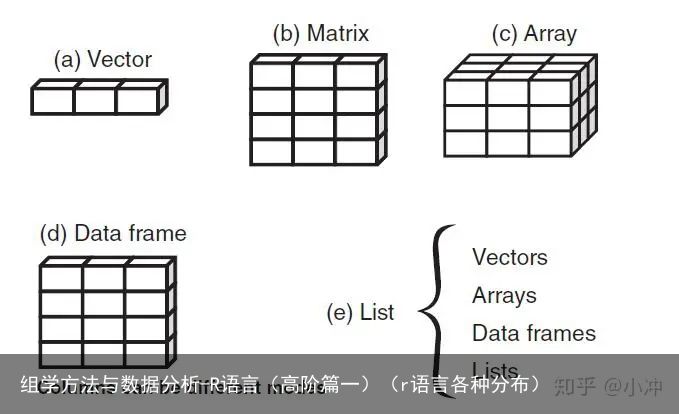 图3 数据对象的类型
图3 数据对象的类型01 Vector
向量(Vector)并非指数学中那个既有方向又有大小的量,而是可以简单理解为一行数字、字符或者逻辑符号(TRUE or FALSE)。R中常用c()构建向量。比如c(0.3,0.5,0.9,0.6,0.3,0.4)为数字向量(Numeric data);c(red,yellow,blue,green,white,black)为字符向量(Character data)【注意字符向量需要用引号将每个字符括起来】;而c(T,F,F,F,T)则为逻辑符号向量(Logical data)。利用class()可以查看对象的数据类型。复制代码,在R中运行一下如下所示:
a <- c(0.3,0.5,0.9,0.6,0.3,0.4) b <- c(red,yellow,blue,green,white,black) c <- c(T,F,F,F,T) class(a) class(b) class(c)需要注意的是:所有逗号,括号等必须用英文符号,否则会报错。比如:
a <- c(0.3,0.5,0.9,0.6,0.3,0.4)
错误: unexpected input in "a <- c(0.3?
#提示0.3后面的符号软件识别不了,所以报错。
再比如逻辑符号必须用TRUE or FALSE或者T or F,如果写成True或False,依然会报错:
c <- c(True,False,False,False,True)
错误: 找不到对象True
#提示True或False软件识别不了,所以报错。
因此代码只有真正上软件多跑几次,才能发现问题,学到更多。
正常运行后的结果如图4所示:
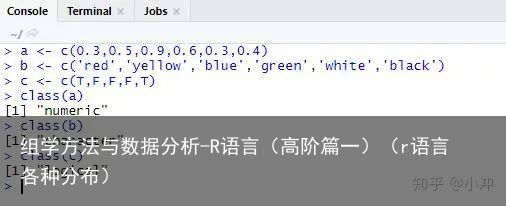 图4 向量数据的类型
图4 向量数据的类型那么不同类型的向量数据可以放在一起吗?比如c(0.3,’red’,T)这样可以吗?没关系啊,上机跑一下就知道有没有问题了。结果如图5所示:可以看出,软件会自动将其认为是字符型向量,实际用到的地方不多。
 图5 不同类型向量“混搭”
图5 不同类型向量“混搭”02 Matrix
矩阵(Matrix)是由n个相同类型的对象组成的二维结构(行列结构),简单来说,就是把一行向量(Vector)变成a行×b列的结构。常说的矩阵为数字矩阵。R中常用matrix()构建矩阵。比如:
a <- c(0.3,0.5,0.9,0.6,0.3,0.4) b <-matrix(a, nrow=2,ncol=3) class(b) view(b)#这里的nrow=2,ncol=3就是将a中的6个数字按照2行(row)×3列(column)的格式,默认按照由第1列到第3列的顺序排布为矩阵。view()函数可帮助我们以直观的表格形式查看这个变量。
运行结果如图6所示:
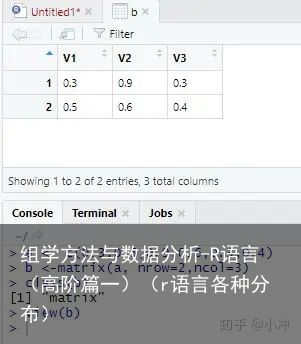 图6 矩阵
图6 矩阵由于矩阵排布默认是按照列的顺序来的,所以如果我们希望它按照行的顺序排布,则需添加byrow=T。此处应修改为b <-matrix(a, nrow=2,ncol=3, byrow=T)。结果如图7所示。
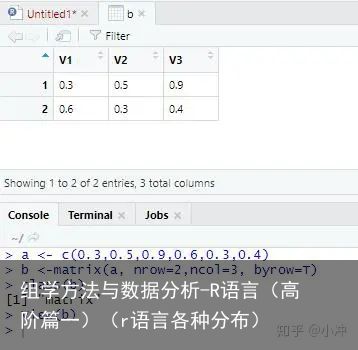 图7 按行排布的矩阵
图7 按行排布的矩阵那么字符型对象可以排布为矩阵吗?不知道的时候上机跑一下就好了,如果不行就会报错。结果如图8所示。
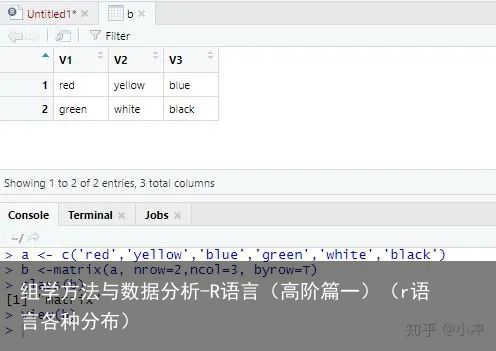 图8 字符型矩阵
图8 字符型矩阵03 Array
数组(Array)是在矩阵的基础上将其扩展至三维结构。R中常用array()构建数组。举个简单的例子来看:
a <- c(1:24) b <-array(a, c(2,3,4)) class(b) b#这里的c(1:24)指的是1到24的所有整数向量按顺序排列。而array()中的c(2,3,4)指的是将这24个整数先后分为4组,每组是一个2×3的矩阵。
运行结果如图9所示:
 图9 数组
图9 数组值得注意的是:数组中的对象必须为同一类型。
04 Data frame
当矩阵中的对象为不同类型时就涉及到数据框(Data frame)的概念了。这么说可能不够形象,其实我们经常填的Excel信息表(比如包含姓名,年龄,体重,性别等信息,每个人的一行信息作为一条记录)就是数据框,也叫数据库。数据框和矩阵是我们在R中最常处理的两类数据。
R中常用data.frame()构建数据框。比如:
name <- c(xiaoming,xiaohong,xiaoliang,xiaohuang) age <- c(18,17,19,18) weight <- c(60,50,65,62) sex <- c(male,female,male,male) studentdata <- data.frame(name,age,weight,sex) class(studentdata) view(studentdata)运行结果如图10所示:
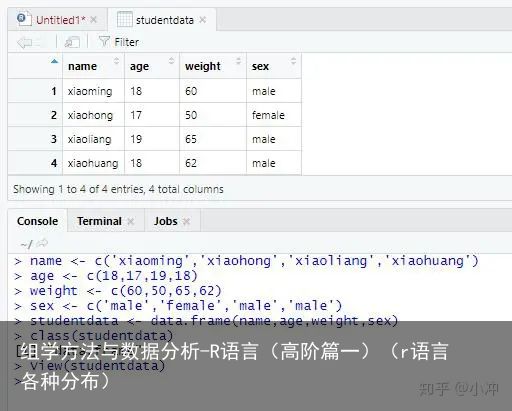 图10 数据框
图10 数据框05 List
列表(List)就是将上述所有类型的数据杂糅在一起。R中常用list ()构建列表,其公式为:
mylist <- list(object1, object2, ...)
每一个对象既可以是向量,也可以是矩阵,甚至时数组或数据框等等。
这里就不举例了,后面操作中看到list后再继续演示。
以上。
