







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
深度学习:读论文《cycleGan》-2020年(读论文有感心得体会格式)
 2023-11-18
2023-11-18 浏览次数:次
浏览次数:次 返回列表
返回列表hello,大家好,我是小孟,欢迎来到我的频道,如果喜欢,请三连:关注、点赞、转发。您的支持是我创作的动力源泉。今天我们来读一篇论文,全名《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,简称cycleGan,是上一篇《Image-to-Image Translation》网络的继承和发展,而且是同一个作者,该模型可以使用非成对的图像数据集训练。
一、作者
朱俊彦,毕业于清华大学本科,毕业后去伯克利读博,在Alexei A. Efros的监督下他获得了加州大学伯克利分校的博士学位。之后,他在 MIT CSAIL 做博士后,与William T. Freeman、 Josh Tenenbaum和Antonio Torralba一起工作。目前是卡内基梅隆大学计算机科学学院机器人研究所的助理教授。他的研究兴趣包括计算机视觉和机器学习,尤其是图像生成和图像编辑方面。
二、摘要
图像到图像的转换是一类视觉和图形问题,其目标是学习使用一组对齐图像对的训练集来建立输入图像和输出图像之间的映射。然而,对于许多任务,成对的训练数据将不可用。本文提出了一种在缺乏成对示例的情况下学习将源域 X 中的图像转换为目标域 Y 的方法。我们的目标是学习一个映射 G:X→Y,使得从 G(X) 中得到的图像分布与使用对抗性损失函数不可区分于 Y 的分布。由于这种映射具有高度的不确定性,因此我们将其与逆映射 F:Y→X 耦合,并引入循环一致性损失以强制执行 F(G(X))≈X(反之亦然)。我们在多个任务上展示了定性结果,其中不存在成对的训练数据,包括收集样式转换、对象变形、季节转换、照片增强等。对比多种先前方法的定量比较结果证明了我们方法的优越性。
三、引言

图1:给定任意两个非序列图片集X和Y,我们的算法学习自动进行转换(左->右)。
1873年的一个美好春日,当克劳德·莫奈(Claude Monet)将他的画架放在阿让特伊河畔附近时,他看到了什么(如图1左上角所示)?如果当时已经有了彩色照片,可能记录了一个清晰的蓝天和倒映着它的一条平静的河流。然而,莫奈通过轻盈的画笔和明亮的调色来表达他对这个场景的印象。
如果莫奈在一个凉爽的夏日傍晚偶然发现了卡西斯的小港口(如图1左下角所示),通过欣赏莫奈的画作,我们可以想象他会如何描绘这个场景:也许是以柔和的色调,突兀的笔触和略显平坦的动态范围来表现。虽然我们从未见过莫奈的画作和对应的照片并排放置,但是我们知道莫奈的画作集和风景照片集。我们可以推断这两个集合之间的风格差异,并想象出如果我们将它们从一个集合转换为另一个集合会是什么样子。
本文提出了一种可以在没有配对训练样本的情况下学习实现此类功能的方法。这个问题可以被广泛描述为图像到图像的转换,即将一种场景的图像从一种表达形式x转换到另一种y,例如从灰度到彩色、从图像到语义标签、从边缘图到照片等等。计算机视觉、图像处理、计算摄影和图形学的多年研究已经在有监督的情况下(如图2左侧所示),即当训练集中有一组成对的图像时,产生了强大的转换系统,例如[11, 19, 22, 23, 28, 33, 45, 56, 58, 62]。
然而,获取成对的训练数据可能是困难和昂贵的。例如,对于像语义分割这样的任务,只有少数几个数据集可用(例如[4]),而且它们相对较小。对于像艺术风格化这样的图形任务,获取输入-输出对可能会更加困难,因为所需的输出非常复杂,通常需要艺术创作。对于许多任务,例如物体转化(例如斑马↔马,图1中上部),所需的输出甚至没有明确的定义。
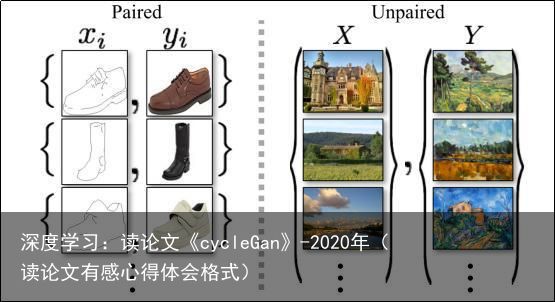
图2:成对训练数据(左)和非成对训练数据(右)
因此,我们需要一个算法,可以学习在没有成对输入输出示例的情况下进行域之间的翻译(图2,右侧)。我们假设域之间存在某种潜在关系——例如,它们是同一基础场景的两种不同呈现方式——并试图学习该关系。虽然我们缺乏成对示例的监督,但我们可以在集合级别上利用监督:我们会得到一个域X中的图像集合和域Y中的不同集合。我们可以训练一个映射G:X → Y,使得输出= G(x),x∈X,无法被对手训练出来将与分类别开来。理论上,这个目标可以诱导的输出分布与经验分布匹配(一般情况下,这需要G是随机的)[16]。
最优的G可以将域X翻译为分布与Y完全相同的域。然而,这样的翻译并不能保证一个单独的输入x和输出y以有意义的方式成对出现——有无限多个映射G会诱导相同的分布。此外,在实践中,我们发现难以仅通过对抗目标进行优化:标准的程序通常会导致众所周知的模式崩溃问题,其中所有输入图像映射到相同的输出图像,优化无法取得进展[15]。
这些问题要求我们在目标上添加更多的结构。因此,我们利用翻译应该是“循环一致”的属性,即如果我们将英语句子翻译成法语,然后再将其从法语翻译回英语,我们应该回到原始句子[3]。从数学上讲,如果我们有一个翻译器G:X → Y和另一个翻译器F:Y → X,则G和F应该是彼此的逆,并且两个映射都应该是双射。我们通过同时训练映射G和F,并添加循环一致性损失[64]来应用这个结构性假设,该损失鼓励和。将这个损失与域X和Y上的对抗损失结合起来,得到了我们用于非成对图像到图像翻译的完整目标。
我们将我们的方法应用于广泛的应用程序,包括集合风格转移、物体变形、季节转移和照片增强。我们还与以前的方法进行了比较,这些方法要么依赖于手工定义的风格和内容的因式分解,要么依赖于共享嵌入函数,并表明我们的方法优于这些基线。我们同时提供了PyTorch和Torch的实现。请在我们的网站(https://junyanz.github.io/CycleGAN/)上查看更多结果。
四、相关工作
生成对抗网络(GAN)[16,63]在图像生成[6,39]、图像编辑[66]和表示学习[39,43,37]方面取得了令人瞩目的成果。最近的方法采用了同样的思路用于条件图像生成应用,如文本到图像[41]、图像修复[38]和未来预测[36],以及其他领域,如视频[54]和3D数据[57]。GAN成功的关键在于对抗损失的思想,强制生成的图像在原则上与真实照片无法区分。对于图像生成任务来说,这种损失尤其强大,因为这恰好是计算机图形学大部分目标要优化的目标。我们采用对抗损失来学习这种映射,使得翻译后的图像与目标领域中的图像无法区分。
图像到图像翻译。图像到图像翻译的想法至少可以追溯到Hertzmann等人的“图像类比”[19],他们在单个输入输出训练图像对上采用非参数纹理模型[10]。更近期的方法使用输入输出示例数据集,使用CNN学习参数化翻译函数(例如[33])。我们的方法基于Isola等人的“pix2pix”框架[22],该框架使用条件生成对抗网络[16]学习从输入图像到输出图像的映射。类似的思想已应用于各种任务,如从草图或属性和语义布局中生成照片[44,25]。但是,与上述先前工作不同,我们学习映射而不需要成对的训练示例。
无配对图像到图像翻译。还有其他一些方法也处理无配对的设置,目标是关联两个数据领域:X和Y。Rosales等人[42]提出了一个贝叶斯框架,其中包括基于从源图像计算的基于补丁的Markov随机场的先验项和从多个样式图像获取的似然项。最近,CoGAN[32]和交叉模态场景网络[1]使用权重共享策略来学习跨领域的共同表示。与我们的方法并行的是,Liu等人[31]扩展了上述框架,使用变分自编码器[27]和生成对抗网络[16]的组合。另一条并行线路的工作[46、49、2]鼓励输入和输出共享特定的“内容”特征,即使它们在“样式”上可能不同。这些方法也使用对抗网络,加上额外的项来强制输出在预定义的度量空间中接近于输入,如类标签空间[2]、图像像素空间[46]和图像特征空间[49]。
与上述方法不同的是,我们的公式不依赖于任何任务特定的、预定义的输入和输出之间的相似度函数,也不假设输入和输出必须位于相同的低维嵌入空间中。这使我们的方法成为许多视觉和图形任务的通用解决方案。我们在第5.1节中直接与几种先前和现代方法进行比较。
循环一致性。使用传递性作为一种来正则结构化数据的想法由来已久。在视觉跟踪中,强制进行简单的正反向一致性已经是几十年来的标准技巧[24, 48]。在语言领域,通过“反向翻译和调和”来验证和改善翻译是人类翻译家[3](包括幽默地马克·吐温[51])以及机器翻译的一种技术。近年来,更高阶的循环一致性已经被用于运动结构[61]、3D形状匹配[21]、共分割[55]、密集的语义对齐[65, 64]和深度估计[14]等领域。其中,Zhou等人[64]和Godard等人[14]最类似于我们的工作,因为他们使用循环一致性损失来使用传递性监督卷积神经网络训练。在本工作中,我们引入了类似的损失来促使G和F相互一致。同时,Yi等人[59]在这些会议中独立地使用类似的目标来进行非配对图像到图像的翻译,受到机器翻译中的双重学习的启发。
神经风格迁移是进行图像到图像转换的另一种方法[13, 23, 52, 12],它通过匹配预先训练的深度特征的Gram矩阵统计数据,将一个图像的内容与另一个图像(通常是一幅绘画)的风格结合起来,从而合成出一幅新的图像。与此相反,我们的主要关注点是学习两个图像集合之间的映射,而不是两个特定图像之间的映射,通过尝试捕捉更高级别的外观结构之间的对应关系。因此,我们的方法可以应用于其他任务,如绘画→照片,物体变形等,这些任务中单个样本转换方法表现不佳。我们在第5.2节中比较了这两种方法。
五、公式表述

图3:(a)模型包含两个映射函数G和F;(b)向前循环一致性损失;(c)向后循环一致性损失。
我们的目标是给定一个训练样本(其中)和(其中),并在X和Y这两个数据域之间学习一个映射函数。我们将数据分布表示为x ∼ 和y ∼ 。如图3(a)所示,我们的模型包括两个映射和。此外,我们引入了两个对抗鉴别器和,其中旨在区分图像{x}和翻译图像{F(y)}之间的差异;同样地,旨在区分{y}和{G(x)}之间的差异。我们的目标包含两种类型的项:对抗性损失[16],用于将生成的图像分布与目标域中的数据分布匹配;以及循环一致性损失,以防止学习到的映射G和F相互矛盾。
5.1、对抗损失
我们对两个映射函数都应用对抗性损失 [16]。对于映射函数 和其判别器 ,我们将目标表示为:

其中,G试图生成看起来与域Y中的图像类似的图像G(x),而旨在区分转换后的样本G(x)和真实样本y。G旨在针对试图最大化此目标的对手D最小化此目标,即 。
我们还引入了类似的对抗性损失来训练映射函数和其判别器:
5.2 周期一致性损失
理论上,对抗性训练可以学习映射函数G和F,使其产生与目标域Y和X分别相同的输出(严格来说,这要求G和F是随机函数)[15]。但是,具有足够大的容量,网络可以将同一组输入图像映射到目标域中的任何随机排列,其中任何学习到的映射都可以引导产生与目标分布相匹配的输出分布。因此,仅凭对抗性损失不能保证学习到的函数能够将单个输入 映射到所需的输出。为了进一步减少可能的映射函数空间,我们认为学习到的映射函数应该是循环一致的:如图3(b)所示,对于来自域X的每个图像x,图像翻译循环应该能够将x带回原始图像,即x → G(x)→ F(G(x))≈ x。我们称之为前向循环一致性。同样,如图3(c)所示,对于来自域Y的每个图像y,G和F还应满足反向循环一致性:y → F(y)→ G(F(y))≈ y。我们使用循环一致性损失来激励这种行为:
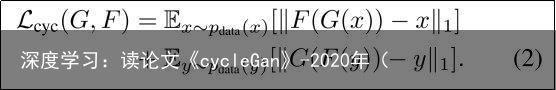
在初步实验中,我们也尝试使用将此损失中的L1范数替换为F(G(x))和x之间以及G(F(y))和y之间的对抗性损失,但是我们没有观察到改善的性能。

图4 各种实验中的输入图像x、输出图像G (x)和重建图像F(G(x))。
通过图4可以观察到由循环一致性损失引起的行为:重建图像F(G(x))最终与输入图像x非常相似。
5.3. 完整目标函数
我们的完整目标函数为:
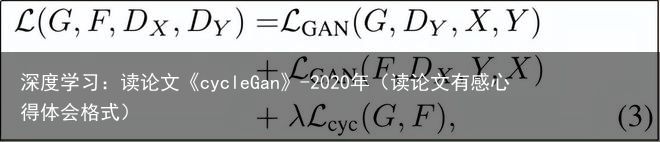
其中, 控制了这两个目标函数的相对重要性。我们的目标是求解:

请注意,我们的模型可以被视为训练了两个“自编码器” [20]:我们同时学习一个自编码器 和另一个 。然而,这些自编码器都有特殊的内部结构:它们通过将图像转换为另一个域的中间表示形式将图像映射回其自身。这种设置也可以看作是“对抗性自编码器”的一种特殊情况[34],其使用对抗性损失来训练自编码器的瓶颈层以匹配任意目标分布。在我们的情况下, 自编码器的目标分布是域 的分布。
在第5.1.4节中,我们将我们的方法与完整目标函数的去除部分进行了比较,包括仅有对抗性损失和仅有循环一致性损失的情况,并通过实验证明了这两个目标函数在达到高质量结果方面发挥了至关重要的作用。我们还使用单向循环损失对我们的方法进行了评估,并表明单个循环不足以对这个欠约束的问题进行训练的规范化。
六、实现
网络架构。我们采用Johnson等人[23]的生成网络架构,该网络在神经风格转移和超分辨率方面已经取得了令人印象深刻的结果。该网络包含三个卷积层,几个残差块[18],两个步长为1/2的分数卷积层和一个将特征映射到RGB的卷积层。对于128×128的图像,我们使用6个块,对于256×256及更高分辨率的训练图像,我们使用9个块。与Johnson等人[23]类似,我们使用实例归一化[53]。对于判别器网络,我们使用70×70的PatchGANs [22, 30, 29],旨在分类70×70重叠的图像块是真实的还是假的。这种基于块级别的鉴别器架构具有比完整图像鉴别器更少的参数,并且可以以全卷积的方式处理任意大小的图像[22]。
训练细节。我们采用了最近的两种技术来稳定我们的模型。首先,在GAN的损失函数(公式1)中,我们用最小二乘损失(least-squares loss)[35]替换了负对数似然损失,这种损失在训练过程中更加稳定,生成的结果更高质量。具体来说,对于GAN的损失函数,我们训练G最小化 ,训练D最小化。
其次,为了减少模型震荡[15],我们遵循Shrivastava等人的策略[46],使用生成的图像历史记录来更新鉴别器,而不是最新生成器产生的图像。我们保留一个图像缓冲区,存储最近创建的50个图像。
对于所有的实验,我们在公式3中设置。我们使用Adam求解器[26],批量大小为1。所有网络都是从头开始训练的,初始学习率为0.0002。在前100个epoch中,我们保持相同的学习率,并将学习率在接下来的100个epoch中线性衰减到零。更多关于数据集、网络架构和训练过程的细节请参见附录(第7节)。
七、结果
我们首先将我们的方法与最近的方法在配对数据集上进行无配对图像转换进行比较,其中可以使用真实的输入输出对进行评估。然后,我们研究了对抗性损失和循环一致性损失的重要性,并将我们的完整方法与几种变体进行比较。最后,我们演示了我们的算法在许多没有配对数据的应用中的通用性。为了简洁起见,我们将我们的方法称为CycleGAN。PyTorch和Torch代码、模型和完整的结果可以在我们的网站上找到。
7.1. 评估
我们使用与“pix2pix”[22]相同的评估数据集和度量标准,从定性和定量两个方面比较我们的方法与几个基线方法。任务包括在Cityscapes数据集[4]上进行语义标签↔照片的转换,以及在从Google地图中抓取的数据上进行地图↔航拍照片的转换。我们还对完整损失函数进行了消融研究。为简洁起见,我们将我们的方法简称为CycleGAN。我们的PyTorch和Torch代码、模型和完整结果可在我们的网站上找到。
AMT 感知研究。在地图↔航拍照片任务中,我们在亚马逊机械土耳其(AMT)上运行“真实 vs 伪造”感知研究,以评估输出的真实性。我们遵循 Isola 等人 [22] 的感知研究协议,但我们仅从每个测试的算法中收集来自 25 个参与者的数据。参与者被展示一系列图像对,一个是真实的照片或地图,另一个是假的(由我们的算法或基线生成),并被要求单击他们认为是真实的图像。每个会话的前 10 次试验是练习,会给予反馈,告诉参与者的反应是正确还是错误。其余的 40 次试验用于评估每个算法愚弄参与者的速率。每个会话只测试一个算法,参与者只能完成一个会话。
我们报告的数字不能直接与 [22] 中的数字进行比较,因为我们的原始图像经过了稍微不同的处理,并且我们测试的参与者群体可能与 [22] 中测试的参与者群体有所不同(由于在不同的日期和时间运行实验)。因此,我们的数字只应与基线(在相同条件下运行的)进行比较,而不应与 [22] 进行比较。
FCN得分。尽管感知研究可能是评估图形逼真程度的黄金标准,但我们还寻求一种不需要人类实验的自动定量测量方法。为此,我们采用了[22]中的“FCN得分”,并将其用于评估Cityscapes标签→照片任务。FCN度量评估了根据现成的语义分割算法(来自[33]的全卷积网络FCN)生成的照片的可解释性。FCN预测了一个生成的照片的标签映射。然后,可以使用下面描述的标准语义分割度量将该标签映射与输入的真实标签进行比较。直觉上,如果我们从“道路上的汽车”标签映射生成一张照片,那么如果应用于生成的照片的FCN检测到“道路上的汽车”,则我们已经成功了。
语义分割度量。为了评估照片→标签的性能,我们使用了Cityscapes基准测试[4]中的标准度量方法,包括像素级准确度、类别级准确度和平均类别交并比(Class IOU)[4]。
7.1.2 基准模型
CoGAN[32]。该方法为X域和Y域分别学习一个GAN生成器,共享前几层的潜在表示权重。从X到Y的翻译可以通过找到一个生成图像X的潜在表示,并将其渲染成风格Y来实现。
SimGAN[46]。与我们的方法类似,Shrivastava等人[46]使用对抗损失来训练从X到Y的翻译。正则化项||x − G(x)||1用于惩罚在像素级别上做出大的变化。
特征损失+GAN。我们还测试了SimGAN [46]的一种变体,其中使用预训练网络(VGG-16 relu4 2 [47])计算深层图像特征上的L1损失,而不是在RGB像素值上计算。像这样在深度特征空间中计算距离有时也被称为使用“感知损失”[8, 23]。
BiGAN/ALI[9, 7]。无条件GANs [16] 学习生成器G:Z → X,将随机噪声z映射到图像x。BiGAN [9]和ALI [7]还提出了学习反向映射函数F:X → Z。尽管它们最初是为将潜在向量z映射到图像x而设计的,但我们实现了同样的目标,将源图像x映射到目标图像y。
pix2pix[22]。我们还将其与pix2pix [22]进行比较,pix2pix是在配对数据上进行训练的,以查看在不使用任何配对数据的情况下,我们可以多接近这个“上限”。
为了公平比较,我们使用与我们的方法相同的架构和细节来实现所有基准模型,除了CoGAN [32]。CoGAN建立在生成器的基础上,这些生成器可以从共享的潜在表示中生成图像,这与我们的图像到图像网络不兼容。我们使用CoGAN的公共实现。
7.1.3 比较各种基准方法

图5:在Cityscapes图像上训练的将标签↔照片进行映射的不同方法。

图6:在Google Maps上训练的将航空照片↔地图进行映射的不同方法。
从图5和图6中可以看出,我们无法通过任何基准方法获得令人信服的结果。相比之下,我们的方法可以产生与完全监督的pix2pix相似质量的翻译结果。

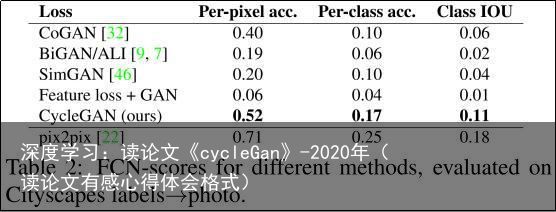
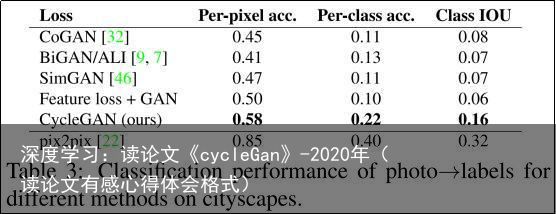
表1报告了AMT感知真实性任务的性能。在256×256分辨率下,我们的方法可以欺骗大约四分之一的参与者,无论是从地图到航空照片方向还是从航空照片到地图方向。而所有基准方法几乎没有欺骗参与者的记录。
表2评估了Cityscapes标签→照片任务的性能,表3评估了相反的映射(照片→标签)。在两种情况下,我们的方法再次优于基准方法。
7.1.4 损失函数分析
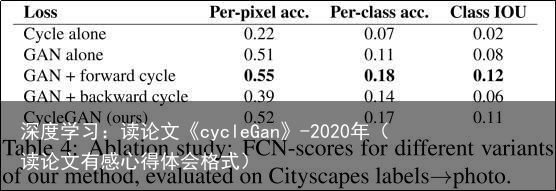
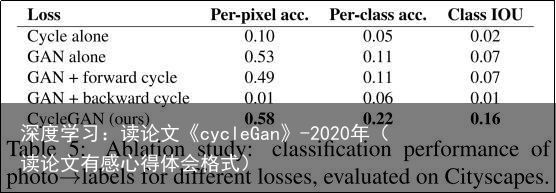
在表4和表5中,我们将完整损失的分解与结果进行了比较。移除GAN损失会显著降低结果,移除循环一致性损失也是如此。因此,我们得出结论,两个术语对我们的结果都至关重要。我们还使用循环损失评估了我们的方法,只在一个方向上使用循环损失:GAN + 前向循环损失 ,或GAN + 后向循环损失 (公式2),并发现它经常导致训练不稳定并且会导致模式坍塌,特别是在删除的映射方向上。 图7显示了几个定性示例。
7.1.5 图像重构质量
在图4中,我们展示了一些重构图像 F(G(x))的随机样本。我们发现,在训练和测试时,即使在一个域表示显著更多的多样化信息,如地图↔航空照片的情况下,重构图像通常都接近于原始输入x。
7.1.6 配对数据集的附加结果
图8显示了一些其他配对数据集上的示例结果,这些数据集被用于“pix2pix”[22],例如来自CMP Facade Database[40]的建筑标签↔照片和来自UT Zappos50K数据集[60]的边缘↔鞋子。我们的结果的图像质量接近于完全监督的pix2pix生成的结果,而我们的方法学习到的映射没有配对监督。

图7:我们在Cityscapes数据集上训练的将标签↔照片进行映射的不同变体的方法。

图8:CycleGAN在“pix2pix” [22]中使用的配对数据集上的示例结果,例如建筑标签↔照片和边缘↔鞋

图9:身份映射损失对于Monet的画作→照片的影响。
7.2 应用
我们展示了我们的方法在几个没有配对训练数据的应用中。更多关于数据集的细节请参见附录(第7节)。我们观察到,对训练数据的翻译通常比对测试数据更有吸引力,所有应用程序的完整结果(包括训练和测试数据)可以在我们的项目网站上查看。
艺术风格转换(图10和图11)。我们从Flickr和WikiArt下载的风景照片上训练模型。与最近关于“神经风格转移”[13]的工作不同,我们的方法学习模仿整个艺术品收藏的风格,而不是仅转移单个选择的艺术品的风格。因此,我们可以学习以例如Van Gogh的风格生成照片,而不仅仅是Starry Night的风格。每个艺术家/风格的数据集大小分别为526、1073、400和563。
物体转换(图13)。模型是在ImageNet [5]中的一个对象类别到另一个类别之间进行训练的(每个类别包含大约1000个训练图像)。Turmukhambetov等人[50]提出了一个子空间模型,将一个对象转换为同一类别中的另一个对象,而我们的方法专注于在两个视觉相似的类别之间进行对象变形。
季节转换(图13)。该模型在来自Flickr的854张冬季照片和1273张夏季照片的优胜美地进行了训练。
从绘画中生成照片(图12)。对于绘画→照片,我们发现引入附加损失有助于鼓励映射保留输入和输出之间的颜色组合。具体而言,我们采用了Taigman等人[49]的技术,并在提供目标域的真实样本作为生成器的输入时,使生成器接近于一个恒等映射:即,。
没有Lidentity的情况下,生成器G和F可以自由地在没有必要的情况下改变输入图像的色调。例如,在学习莫奈(Monet)的绘画和Flickr的照片之间的映射时,生成器经常将白天的绘画映射到在日落时拍摄的照片上,因为这样的映射在对抗性损失和循环一致性损失下可能同样有效。这个身份映射损失的效果如图9所示。
在图12中,我们展示了将莫奈的绘画翻译成照片的额外结果。这张图片和图9展示的是训练集中包含的绘画结果,而在本文的所有其他实验中,我们仅评估和展示测试集的结果。由于训练集不包括成对数据,为训练集绘画创造一个合理的翻译是一个非常棘手的任务。事实上,由于莫奈已经无法创造新的绘画作品,对未见过的“测试集”绘画的泛化不是一个紧迫的问题。
照片增强(图14)。我们展示了我们的方法可以用于生成具有更浅景深的照片。我们从Flickr下载了花朵照片,并在这些照片上训练了模型。源域包含由智能手机拍摄的花朵照片,这些照片通常具有由于光圈较小而产生的深景深。目标域包含由具有更大光圈的DSLR相机拍摄的照片。我们的模型成功地从智能手机拍摄的照片中生成了具有更浅景深的照片。
与Gatys等人[13]的比较。在图15中,我们将我们的结果与神经风格转移[13]在照片样式化方面进行了比较。对于每一行,我们首先使用两个具有代表性的艺术作品作为[13]的样式图像。另一方面,我们的方法可以在整个集合的风格中生成照片。为了将其与整个集合的神经风格转移进行比较,我们计算目标域中的平均Gram矩阵,并使用该矩阵将“平均风格”转移到Gatys等人[13]中。
图16展示了其他翻译任务的类似比较。我们观察到,Gatys等人[13]需要找到与所需输出密切匹配的目标风格图像,但仍经常无法生成逼真的结果,而我们的方法成功地生成了类似于目标域的自然效果。
八、局限和讨论
尽管我们的方法在许多情况下可以实现令人信服的结果,但结果远非一致性积极的。图17展示了几种典型的失败情况。对于那些涉及颜色和纹理变化的翻译任务,像前面报告的许多任务一样,该方法通常会成功。我们还尝试了需要几何变化的任务,但效果不佳。例如,在狗→猫的变形任务中,学习到的翻译结果退化为最小化输入的变化(如图17所示)。这种失败可能是由于我们的生成器架构是为外观变化的良好表现而量身定制的。处理更多样化和极端的变换,尤其是几何变化,是未来工作的重要问题。
一些失败案例是由于训练数据集的分布特征所致。例如,在马→斑马的示例中(图17,右侧),我们的方法因为模型是在ImageNet的野马和斑马synsets上训练的,而该数据集中不包含一个人骑在马或斑马上的图像,所以出现了困惑的情况。
我们也注意到,在使用配对训练数据与使用我们的非配对方法所得到的结果之间,存在一定的差距。在某些情况下,这种差距可能非常大,甚至不可能弥合:例如,我们的方法有时会在将照片转化为标签的输出中对树和建筑物的标签进行置换。解决这种歧义可能需要某种形式的弱语义监督。整合弱或半监督数据可能会带来更加强大的翻译器,而且成本只是全监督系统注释成本的一小部分。尽管如此,在许多情况下,完全非配对数据是充足可用的,应该加以利用。本文推动了在这种“无监督”环境下的可能性边界。
九、部分引用
[16] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014.
[23] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution.
[35] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. P. Smolley. Least squares generative adversarial networks. In CVPR. IEEE, 2017.
[46] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, 2017.
十、附加材料

图10:收集风格转移I:我们将输入图像转换为Monet、Van Gogh、Cezanne和Ukiyo-e的艺术风格。

图11:收集风格转移II:我们将输入图像转换为Monet、Van Gogh、Cezanne、Ukiyo-e的艺术风格。

图12:将Monet的画作映射到照片风格的相对成功的结果。
图13:我们的方法应用于多个翻译问题。
图14:照片增强:将一组智能手机快照映射到专业DSLR照片,系统通常学会产生浅景深效果。
图15:我们将我们的方法与神经风格转移[13]在照片风格化方面进行比较。
图16:我们将我们的方法与神经风格转移[13]在各种应用中进行比较。
图17:我们方法的典型失败案例。
