







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据分析师招聘知多少
 2023-03-21
2023-03-21 浏览次数:次
浏览次数:次 返回列表
返回列表随着社会的进步,从原来拍脑门解决业务发展到现在的数据驱动业务,数据分析师这个职位也逐渐展露出他应有的职能。今天我们就来看看当下公司对数据分析师的一些要求及钱途如何。
本次数据获取 当下某招聘网站全国的数据分析师岗位信息,如下:
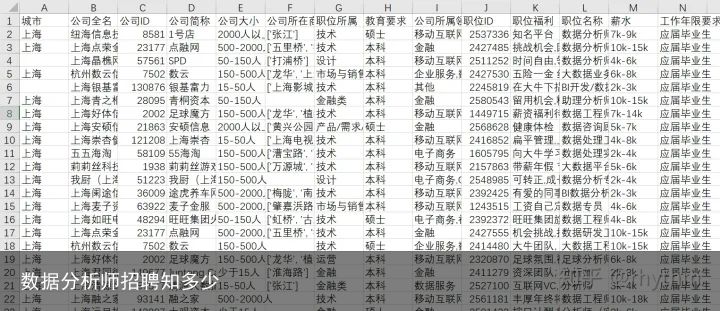 图一
图一一、提出问题
在哪些城市找到数据分师工作的机会比较大? 数据分师的薪水如何? 根据工作经验的不同,薪酬是怎样变化的?二、理解数据
在图一中我们可以看到一共有4个字段
 图二
图二三、数据清洗
一般的清晰步骤为:
 图三
图三1、选择子集
保留对数据分析有意义的字段,无意义的字段隐藏掉。
2、列名重命名
将列名更改为我们容易理解的形式。
3、删除重复值
对重复字段删除,这里我们对“职场ID”列进行删除重复值处理。
4、缺失值处理
对关键字段进行检查是否有缺失值
本次我们通过选取“城市”与“职场ID”列,在右下角计数项发现“城市”列有两个缺失值。
注:补全时先定位条件,定位到空值然后Ctrl + Enter全部不全空值。
缺失值处理的 4 种方法:
①通过人工手动补全②删除缺失的数据③用平均值代替缺失值④用统计模型计算出的值去代替缺失值5、一致化处理
我们需要对现有数据进行统一标准处理,以便于后期计算与建模
(1)再第一步中我们已经熟悉过个字段意义,所以这一步首先,我们对“公司所属领域”进行分列处理,记得要将数据先复制到最后一列,因为分列功能会覆盖掉右列单元格。(PS:之所以分裂改行目的在于后期门分析中便于针对某个领域的数据分析职位进行分析。)
(2)接下来,我们将薪水处理成“最低薪水”,“最高薪水”,“平均薪资”(将最低、最高薪资使用“平均函数”即可计算,下文不予赘述)
方法有两种:
分裂法公式法注1:其中公式法主要涉及公式:
 图四
图四注2 :公式所得数据为文本类型,无法进行公式计算所以这里需要进行格式的转换。转换时用分裂功能进行更改(具体操作见图五、六)。
 图五
图五 图六
图六6、数据排序
我们对“平均薪水"进行降序排列。
7、异常值处理
观察我们现有字段哪个字段对我们分析问题最有帮助,可以看出”职位名称“这个字段很重要。因为我们是”分析数据分析师“这个职位,如果参杂了其他职位标签会影响我们后面的分析,无用功。
当我们找到关键字段以后,进行数据透视,观察是否有异常值,发现有很多不相关职位,需要进行处理。
接下来我们要处理掉这些异常值,利用函数{=IF(COUNT(FIND({"数据运营","数据分析","分析师"},L4)),"是","否")}。最后筛选出符合数据分析师的职位,并将结果保存到另外一张表上。到此数据清洗的所有步骤已完成。结果如下:
 图七
图七四、构建模型
1、在哪些城市找到数据分师工作的机会比较大?
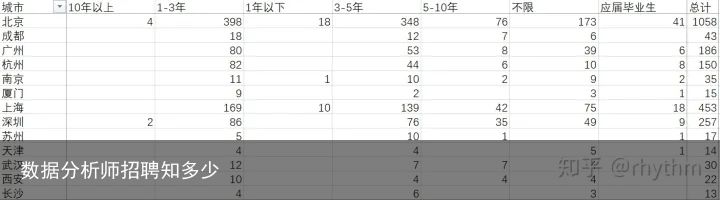 图八
图八由图八可以看出:北京的数据分析工作机会最多,其他依次是上海、深圳、广州、杭州。
接下来我们利用Excel的数据分析工具对平均薪水进行描述统计(主要运用加载项分析工具中描述统计),结果如下:
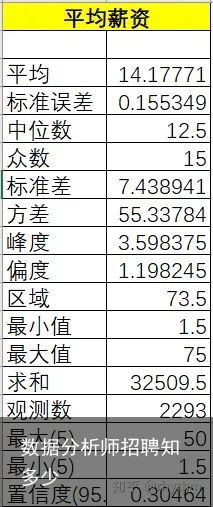 图九
图九2、数据分师的薪水如何?
 图十
图十由图十可知:一线城市平均薪资再15K左右,由此可见数据分析这个职位还是很有钱途的。
3、根据工作经验的不同,薪酬是怎样变化的?
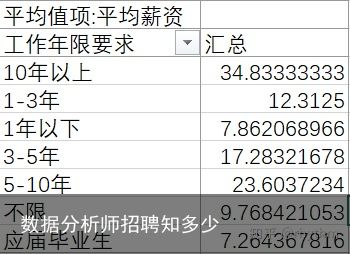 图十一
图十一由图十一可以看出:数据分析师随着工作年限的提高薪资也逐渐上升。
五、总结
通过上面的分析,我们可以得到的以下分析结论有:
数据分析这一岗位,有大量的工作机会集中在北上广深以及新一线城市,如果将来去这些城市找工作,可以提高成功的条件概率。 数据分析是个年轻的职业方向,大量的工作经验需求集中在1-3年。 对于数据分析师来说,5年似乎是个瓶颈期,如果在5年之内没有提升自己的能力,大概以后的竞争压力会比较大。 随着经验的提升,数据分析师的薪酬也在不断提高,10年以上工作经验的人,能获得相当丰厚的薪酬。